| Citation: | Shanmin WANG, Hui SHUAI, Lei ZHU, et al., “Expression Complementary Disentanglement Network for Facial Expression Recognition,” Chinese Journal of Electronics, vol. 33, no. 3, pp. 1–11, 2024 doi: 10.23919/cje.2022.00.351

|
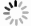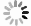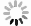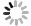
| [1] |
C. Wang, J. Xue, K. Lu, et al., “Light attention embedding for facial expression recognition,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 4, pp. 1834–1847, 2022. doi: 10.1109/TCSVT.2021.3083326
|
| [2] |
Y. J. Li, Y. Lu, B. Z. Chen, et al., “Learning informative and discriminative features for facial expression recognition in the wild,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 5, pp. 3178–3189, 2022. doi: 10.1109/TCSVT.2021.3103760
|
| [3] |
M. Y. Huang, X. M. Zhang, X. Y. Lan, et al., “Convolution by multiplication: Accelerated two- stream Fourier domain convolutional neural network for facial expression recognition,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 3, pp. 1431–1442, 2022. doi: 10.1109/TCSVT.2021.3073558
|
| [4] |
S. L. Dai and H. Man, “Mixture statistic metric learning for robust human action and expression recognition,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 28, no. 10, pp. 2484–2499, 2018. doi: 10.1109/tcsvt.2017.2772026
|
| [5] |
W. C. Xie, H. Q. Wu, Y. Tian, et al., “Triplet loss with multistage outlier suppression and class-pair margins for facial expression recognition,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 2, pp. 690–703, 2022. doi: 10.1109/TCSVT.2021.3063052
|
| [6] |
S. M. Wang, H. Shuai, and Q. S. Liu, “Phase space reconstruction driven spatio-temporal feature learning for dynamic facial expression recognition,” IEEE Transactions on Affective Computing, vol. 13, no. 3, pp. 1466–1476, 2022. doi: 10.1109/taffc.2020.3007531
|
| [7] |
J. Z. Xia, D. T. P. Quynh, Y. He, et al., “Modeling and compressing 3-D facial expressions using geometry videos,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 22, no. 1, pp. 77–90, 2012. doi: 10.1109/TCSVT.2011.2158337
|
| [8] |
Y. L. Xue, X. Mao, C. D. Caleanu, et al., “Layered fuzzy facial expression generation of virtual agent,” Chinese Journal of Electronics, vol. 19, no. 1, pp. 69–74, 2010.
|
| [9] |
S. L. Wang, H. H. Chi, Z. Q. Yuan, et al., “Emotion recognition using cloud model,” Chinese Journal of Electronics, vol. 28, no. 3, pp. 470–474, 2019. doi: 10.1049/cje.2018.09.020
|
| [10] |
L. Lin and L. Tan, “Multi-distributed speech emotion recognition based on mel frequency cepstogram and parameter transfer,” Chinese Journal of Electronics, vol. 31, no. 1, pp. 155–167, 2022. doi: 10.1049/cje.2020.00.080
|
| [11] |
H. J. Zhao, N. Ye, and R. C. Wang, “Improved cross-corpus speech emotion recognition using deep local domain adaptation,” Chinese Journal of Electronics, vol. 32, no. 3, pp. 640–646, 2023. doi: 10.23919/cje.2021.00.196
|
| [12] |
Wang S, Shuai H, Liu C, et al., “Bias-based soft label learning for facial expression recognition,” IEEE Transactions on Affective Computing, vol. 1, pp. 1–12, 2022. doi: 10.1109/TAFFC.2022.3220291
|
| [13] |
H. B. Liao, D. H. Wang, P. Fan, et al., “Deep learning enhanced attributes conditional random forest for robust facial expression recognition,” Multimedia Tools and Applications, vol. 80, no. 19, pp. 28627–28645, 2021. doi: 10.1007/s11042-021-10951-8
|
| [14] |
R. R. Ni, B. Yang, X. Zhou, et al., “Facial expression recognition through cross-modality attention fusion,” IEEE Transactions on Cognitive and Developmental Systems, vol. 15, no. 1, pp. 175–185, 2023. doi: 10.1109/TCDS.2022.3150019
|
| [15] |
R. R. Ni, X. F. Liu, Y. Z. Chen, et al., “Negative emotions sensitive humanoid robot with attention-enhanced facial expression recognition network,” Intelligent Automation & Soft Computing, vol. 34, no. 1, pp. 149–164, 2022. doi: 10.32604/iasc.2022.026813
|
| [16] |
Q. F. Yang, C. J. Li, and Z. J. Li, “Application of FTGSVM algorithm in expression recognition of fatigue driving,” Journal of Multimedia, vol. 9, no. 4, pp. 527–533, 2014.
|
| [17] |
M. S. Bartlett and J. Whitehill, “Automated facial expression measurement: Recent applications to basic research in human behavior, learning, and education,” in Oxford Handbook of Face Perception, A. J. Calder, G. Rhodes, M. H. Johnson, et al., Eds. Oxford University Press, Oxford, UK, pp. 489–514, 2011.
|
| [18] |
M. S. Bartlett, G. Littlewort, I. Fasel, et al., “Real time face detection and facial expression recognition: Development and applications to human computer interaction,” in Proceedings of 2003 Conference on Computer Vision and Pattern Recognition Workshop, Madison, WI, USA, pp. 53, 2003.
|
| [19] |
J. Q. Fan, K. H. Zhang, Y. Q. Zhao, et al., “Unsupervised video object segmentation via weak user interaction and temporal modulation,” Chinese Journal of Electronics, vol. 32, no. 3, pp. 507–518, 2023. doi: 10.23919/cje.2022.00.139
|
| [20] |
S. Li, W. H. Deng, and J. P. Du, “Reliable crowdsourcing and deep locality-preserving learning for expression recognition in the wild,” in Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, pp. 2584–2593, 2017.
|
| [21] |
A. Mollahosseini, B. Hasani, and M. H. Mahoor, “AffectNet: A database for facial expression, valence, and arousal computing in the wild,” IEEE Transactions on Affective Computing, vol. 10, no. 1, pp. 18–31, 2019. doi: 10.1109/TAFFC.2017.2740923
|
| [22] |
A. Caroppo, A. Leone, and P. Siciliano, “Comparison between deep learning models and traditional machine learning approaches for facial expression recognition in ageing adults,” Journal of Computer Science and Technology, vol. 35, no. 5, pp. 1127–1146, 2020. doi: 10.1007/s11390-020-9665-4
|
| [23] |
N. M. Yao, H. Chen, Q. P. Guo, et al., “Non-frontal facial expression recognition using a depth-patch based deep neural network,” Journal of Computer Science and Technology, vol. 32, no. 6, pp. 1172–1185, 2017. doi: 10.1007/s11390-017-1792-1
|
| [24] |
H. Y. Li, W. M. Dong, and B. G. Hu, “Facial image attributes transformation via conditional recycle generative adversarial networks,” Journal of Computer Science and Technology, vol. 33, no. 3, pp. 511–521, 2018. doi: 10.1007/s11390-018-1835-2
|
| [25] |
Z. Q. Zhao and Q. S. Liu, “Former-DFER: Dynamic facial expression recognition transformer,” in Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, China, pp. 1553–1561, 2021.
|
| [26] |
Z. Q. Zhao, Q. S. Liu, and S. M. Wang, “Learning deep global multi-scale and local attention features for facial expression recognition in the wild,” IEEE Transactions on Image Processing, vol. 30, pp. 6544–6556, 2021. doi: 10.1109/TIP.2021.3093397
|
| [27] |
K. Ali and C. E. Hughes, “Facial expression recognition by using a disentangled identity-invariant expression representation,” in Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, pp. 9460–9467, 2021.
|
| [28] |
S. Y. Xie, H. F. Hu, and Y. Z. Chen, “Facial expression recognition with two-branch disentangled generative adversarial network,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 6, pp. 2359–2371, 2021. doi: 10.1109/TCSVT.2020.3024201
|
| [29] |
R. L. Wu and S. J. Lu, “LEED: Label-free expression editing via disentanglement,” in Proceedings of the 16th European Conference on Computer Vision, Glasgow, UK, pp. 781–798, 2020.
|
| [30] |
W. Zhang, X. P. Ji, K. Y. Chen, et al., “Learning a facial expression embedding disentangled from identity,” in Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, pp. 6755–6764, 2021.
|
| [31] |
G. Liang, S. F. Wang, and C. Wang, “Pose-aware adversarial domain adaptation for personalized facial expression recognition,” arXiv preprint, arXiv: 2007.05932, 2020.
|
| [32] |
R. Y. Mo, Y. Yan, J. H. Xue, et al., “D3Net: Dual-branch disturbance disentangling network for facial expression recognition,” in Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, China, pp. 779–781, 2021.
|
| [33] |
Q. Zhu, L. J. Gao, H. P. Song, et al., “Learning to disentangle emotion factors for facial expression recognition in the wild,” International Journal of Intelligent Systems, vol. 36, no. 6, pp. 2511–2527, 2021. doi: 10.1002/int.22391
|
| [34] |
M. Halawa, M. Wöllhaf, E. Vellasques, et al., “Learning disentangled expression representations from facial images,” arXiv preprint, arXiv: 2008.07001, 2020.
|
| [35] |
X. F. Liu, B. V. K. Vijaya Kumar, J. You, et al., “Adaptive deep metric learning for identity-aware facial expression recognition,” in Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, pp. 522–531, 2017.
|
| [36] |
A. Creswell, T. White, V. Dumoulin, et al., “Generative adversarial networks: An overview,” IEEE Signal Processing Magazine, vol. 35, no. 1, pp. 53–65, 2018. doi: 10.1109/MSP.2017.2765202
|
| [37] |
Y. F. Xia, W. B. Zheng, Y. M. Wang, et al., “Local and global perception generative adversarial network for facial expression synthesis,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 3, pp. 1443–1452, 2022. doi: 10.1109/TCSVT.2021.3074032
|
| [38] |
G. E. Hinton and R. R. Salakhutdinov, “Reducing the dimensionality of data with neural networks,” Science, vol. 313, no. 5786, pp. 504–507, 2006. doi: 10.1126/science.1127647
|
| [39] |
X. F. Liu, B. V. K. Vijaya Kumar, P. Jia, et al., “Hard negative generation for identity-disentangled facial expression recognition,” Pattern Recognition, vol. 88, pp. 1–12, 2019. doi: 10.1016/j.patcog.2018.11.001
|
| [40] |
D. P. Kingma and M. Welling, “Auto-encoding variational Bayes,” in Proceedings of the 2nd International Conference on Learning Representations, Banff, AB, Canada, pp. 1-14, 2014.
|
| [41] |
M. Jaderberg, K. Simonyan, A. Zisserman, et al., “Spatial transformer networks,” in Proceedings of the 28th International Conference on Neural Information Processing Systems, Cambridge, MA, USA, pp. 2017–2025, 2015.
|
| [42] |
Z. X. Shu, M. Sahasrabudhe, R. A. Güler, et al., “Deforming autoencoders: Unsupervised disentangling of shape and appearance,” in Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, pp. 664–680, 2018.
|
| [43] |
X. L. Xing, R. Q. Gao, T. Han, et al., “Deformable generator networks: Unsupervised disentanglement of appearance and geometry,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 3, pp. 1162–1179, 2022. doi: 10.1109/TPAMI.2020.3013905
|
| [44] |
H. Y. Yang, Z. Zhang, and L. J. Yin, “Identity-adaptive facial expression recognition through expression regeneration using conditional generative adversarial networks,” in 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, pp. 294–301, 2018.
|
| [45] |
C. Wang and S. F. Wang, “Personalized multiple facial action unit recognition through generative adversarial recognition network,” in Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, pp. 302–310, 2018.
|
| [46] |
H. Y. Yang, U. Ciftci, and L. J. Yin, “Facial expression recognition by de-expression residue learning,” in Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, pp. 2168–2177, 2018.
|
| [47] |
D. L. Ruan, R. Y. Mo, Y. Yan, et al., “Adaptive deep disturbance-disentangled learning for facial expression recognition,” International Journal of Computer Vision, vol. 130, no. 2, pp. 455–477, 2022. doi: 10.1007/s11263-021-01556-7
|
| [48] |
J. Johnson, A. Alahi, and F.F.Li , “Perceptual losses for real-time style transfer and super-resolution,” in Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, pp. 694–711, 2016.
|
| [49] |
J. Lee, S. Kim, S. Kim, et al., “Context-aware emotion recognition networks,” in Proceedings of 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), pp. 10142–10151, 2019.
|
| [50] |
J. W. Shi and S. H. Zhu, “Learning to amend facial expression representation via de-albino and affinity,” arXiv preprint, arXiv: 2103.10189, 2021.
|
| [51] |
J. K. Deng, J. Guo, Y. X. Zhou, et al., “RetinaFace: Single-stage dense face localisation in the wild,” arXiv preprint, arXiv: 1905.00641, 2019.
|
| [52] |
B. Y. Chen, W. L. Guan, P. X. Li, et al., “Residual multi-task learning for facial landmark localization and expression recognition,” Pattern Recognition, vol. 115, article no. 107893, 2021. doi: 10.1016/j.patcog.2021.107893
|
| [53] |
R. Gross, I. Matthews, J. Cohn, et al., “Multi-PIE,” Image and Vision Computing, vol. 28, no. 5, pp. 807–813, 2010. doi: 10.1016/j.imavis.2009.08.002
|
| [54] |
S. C. Y. Hung, J. H. Lee, T. S. T. Wan, et al., “Increasingly packing multiple facial-informatics modules in a unified deep-learning model via lifelong learning,” in Proceedings of the 2019 on International Conference on Multimedia Retrieval, Ottawa, ON, Canada, pp. 339–343, 2019.
|
| [55] |
F. Schroff, D. Kalenichenko, and J. Philbin, “FaceNet: A unified embedding for face recognition and clustering,” in Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, pp. 815–823, 2015.
|
| [56] |
M. Sandler, A. Howard, M. L. Zhu, et al., “MobileNetV2: Inverted residuals and linear bottlenecks,” in Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, pp. 4510–4520, 2018.
|
| [57] |
K. M. He, X. Y. Zhang, S. Q. Ren, et al., “Deep residual learning for image recognition,” in Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, pp. 770–778, 2016.
|
| [58] |
S. H. Gao, M. M. Cheng, K. Zhao, et al., “Res2Net: A new multi-scale backbone architecture,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 2, pp. 652–662, 2021. doi: 10.1109/TPAMI.2019.2938758
|
| [59] |
Z. Q. Zhao, Q. S. Liu, and F. Zhou, “Robust lightweight facial expression recognition network with label distribution training,” in Proceedings of the 35th AAAI Conference on Artificial Intelligence, Virtual Event, pp. 3510–3519, 2021.
|
| [60] |
K. Wang, X. J. Peng, J. F. Yang, et al., “Suppressing uncertainties for large-scale facial expression recognition,” in Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, pp. 6896–6905, 2020.
|

Figures(5) / Tables(7)

CJE QR CODE

CIE QR CODE
Copyright © Editorial Office of Chinese Journal of Electronics | 京ICP备12041980号-1 |
Supported by:
Beijing Renhe Information Technology Co. Ltd




 DownLoad:
DownLoad: