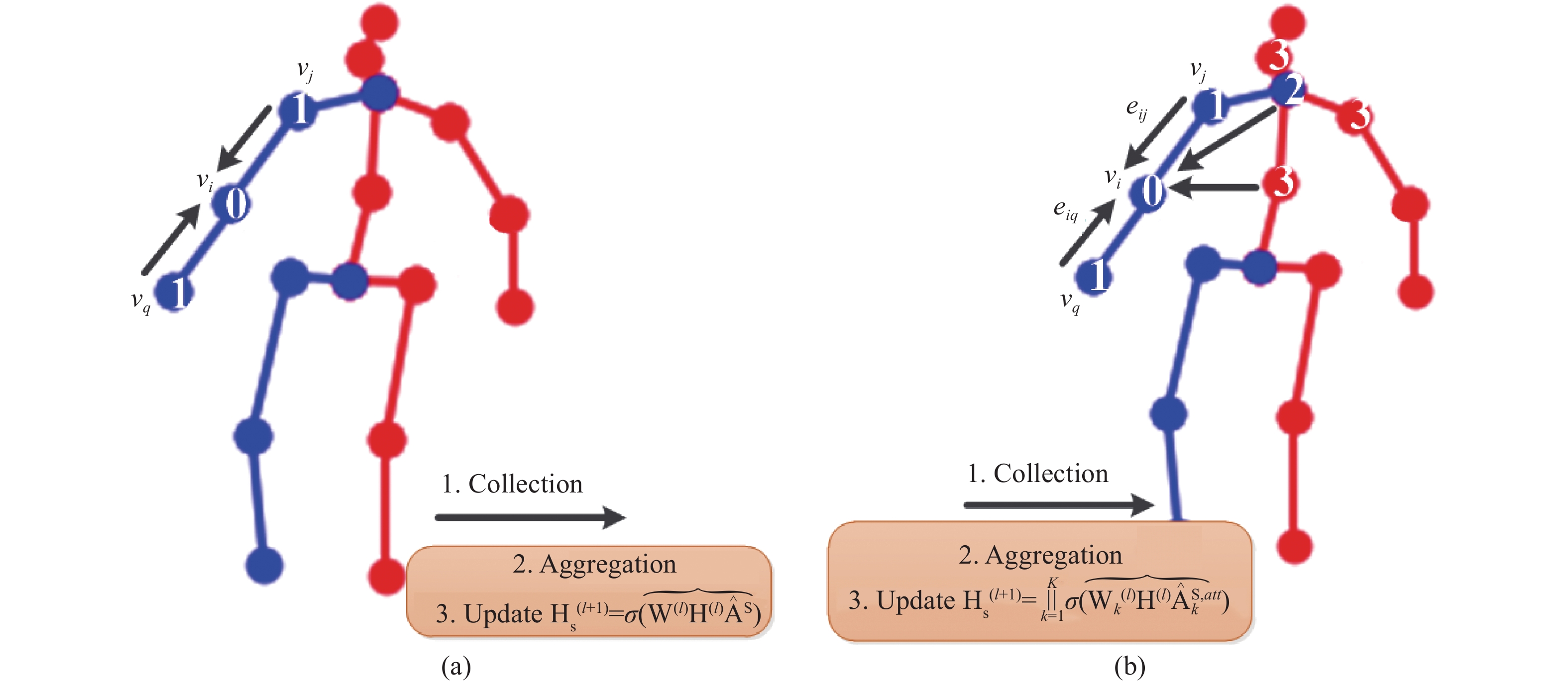
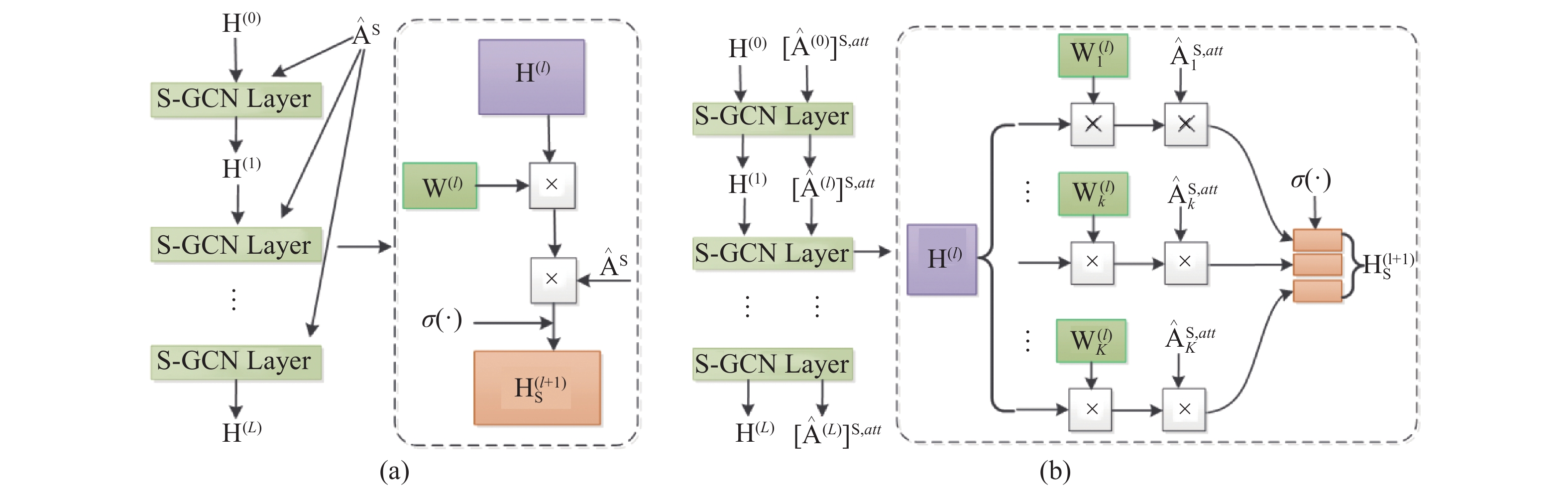
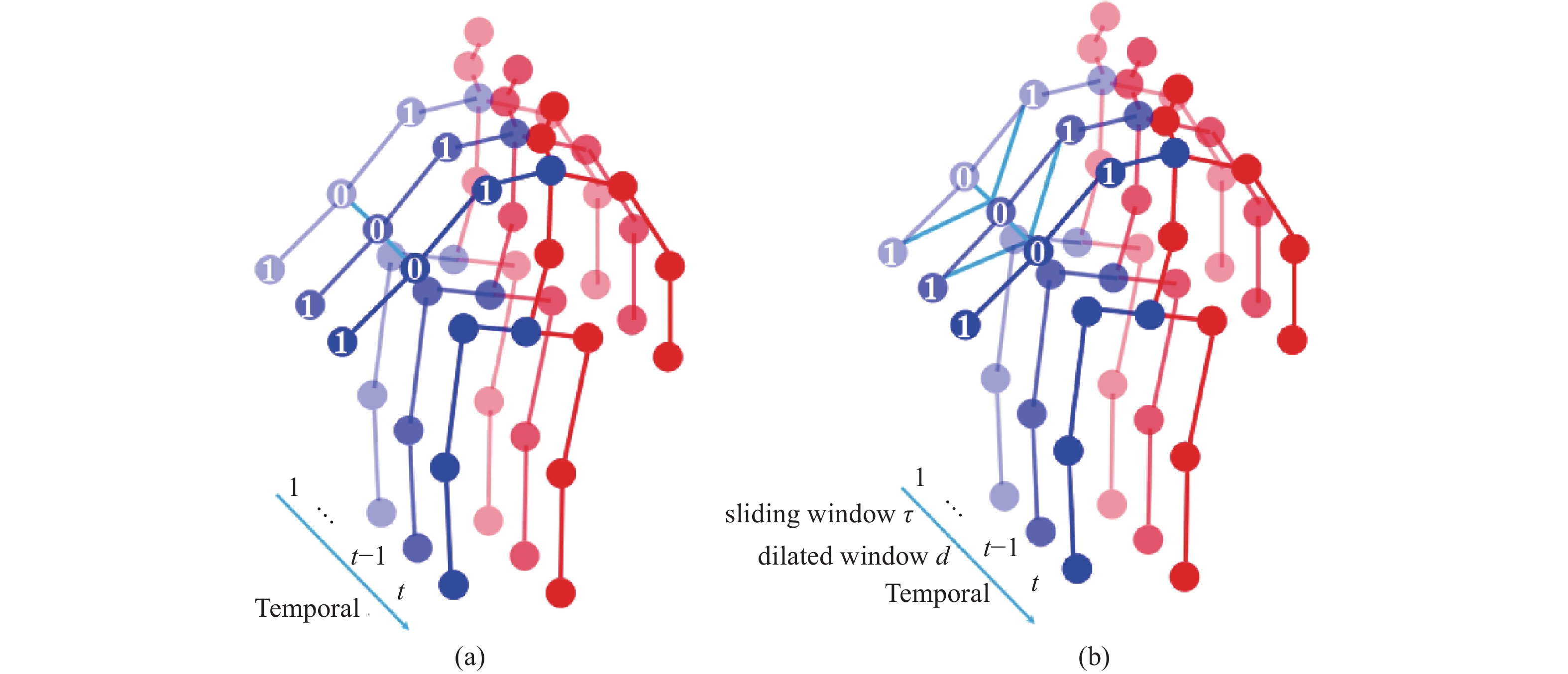
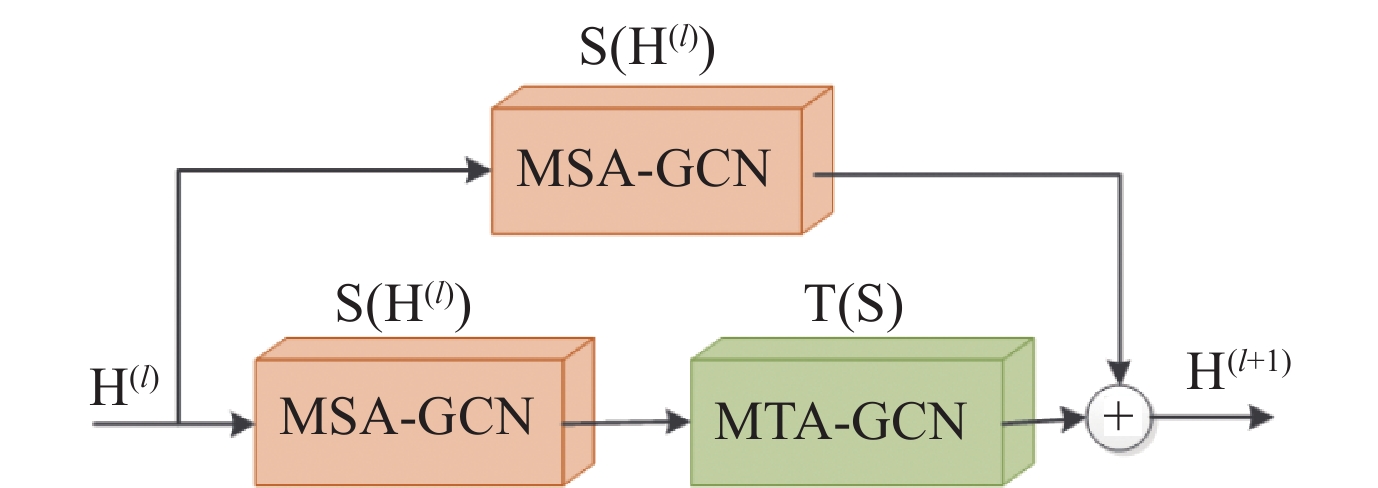
| Citation: | Honghong YANG, Hongxi LIU, Yumei ZHANG, et al., “FMR-GNet: Forward Mix-hop spatial-temporal Residual Graph Network for 3D Pose estimation,” Chinese Journal of Electronics, vol. x, no. x, pp. 1–14, xxxx doi: 10.23919/cje.2022.00.365

|
| [1] |
Q. Guan, Z. H. Sheng, and S. B. Xue, “Hrpose: Real-time high-resolution 6d pose estimation network using knowledge distillation,” Chinese Journal of Electronics, vol. 32, no. 1, pp. 189–198, 2023. doi: 10.23919/cje.2021.00.211
|
| [2] |
H. H. Yang, J. C. Shang, J. J. Li, et al., “Multi-traffic targets tracking based on an improved structural sparse representation with spatial-temporal constraint,” Chinese Journal of Electronics, vol. 31, no. 2, pp. 266–276, 2022. doi: 10.1049/cje.2020.00.007
|
| [3] |
W. H. Li, H. Liu, H. Tang, et al., “MHFormer: Multi-hypothesis transformer for 3D human pose estimation,” in Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, pp. 13137–13146, 2022.
|
| [4] |
G. Pavlakos, X. W. Zhou, K. G. Derpanis, et al., “Coarse-to-fine volumetric prediction for single-image 3D human pose,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 2017.
|
| [5] |
X. Sun, B. Xiao, F. Y. Wei, et al., “Integral human pose regression,” in 15th European Conference on Computer Vision, Munich, Germany, 2018.
|
| [6] |
G. Moon and K. M. Lee, “I2L-meshnet: Image-to-lixel prediction network for accurate 3D human pose and mesh estimation from a single RGB image,” in 16th European Conference on Computer Vision, Glasgow, UK, 2020.
|
| [7] |
G. Pavlakos, X. W. Zhou, and K. Daniilidis, “Ordinal depth supervision for 3D human pose estimation,” in Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, pp. 7307–7316, 2018.
|
| [8] |
K. K. Liu, R. Q. Ding, Z. M. Zou, et al., “A comprehensive study of weight sharing in graph networks for 3D human pose estimation,” in 16th European Conference on Computer Vision, Glasgow, UK, 2020.
|
| [9] |
T. H. Xu and W. Takano, “Graph stacked hourglass networks for 3D human pose estimation,” in Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, pp. 16100–16109, 2021.
|
| [10] |
Y. J. Cai, L. H. Ge, J. Liu, et al., “Exploiting spatial-temporal relationships for 3D pose estimation via graph convolutional networks,” in 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea (South), 2019.
|
| [11] |
C. Zheng, S. J. Zhu, M. Mendieta, et al., “3D human pose estimation with spatial and temporal transformers,” in Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, pp. 11656–11665, 2021.
|
| [12] |
J. B. Wang, S. J. Yan, Y. J. Xiong, et al., “Motion guided 3D pose estimation from videos,” in 16th European Conference on Computer Vision, Glasgow, UK, pp. 764–780, 2020.
|
| [13] |
L. Zhao, X. Peng, Y. Tian, et al., “Semantic graph convolutional networks for 3D human pose regression,” in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 2019.
|
| [14] |
J. J. Huang, Z. H. Li, N. N. Li, et al., “AttPool: Towards hierarchical feature representation in graph convolutional networks via attention mechanism,” in 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea (South), 2019.
|
| [15] |
J. F. Liu, J. Rojas, Y. H. Li, et al., “A graph attention spatio-temporal convolutional network for 3D human pose estimation in video,” in 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, pp. 3374–3380, 2021.
|
| [16] |
Z. Y. Liu, H. W. Zhang, Z. H. Chen, et al., “Disentangling and unifying graph convolutions for skeleton-based action recognition,” in Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, pp. 140–149, 2020.
|
| [17] |
Z. M. Bai, H. P. Yan, and L. F. Wang, “High-order graph convolutional network for skeleton-based human action recognition,” in Second Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Xi’an, China, 2019
|
| [18] |
Z. Zou, K. Liu, L. Wang, et al., “High-order graph convolutional networks for 3D human pose estimation,” in British Machine Vision Conference, Manchester, UK, 2020.
|
| [19] |
J. Liu, Y. Guang, and J. Rojas, “Gast-net: Graph attention spatiotemporal convolutional networks for 3D human pose estimation in video,” arXiv preprint, arXiv, in press, 2020. (查阅网上资料, 未找到本条文献信息, 请确认)
|
| [20] |
H. Li, B. W. Shi, W. R. Dai, et al., “Pose-oriented transformer with uncertainty-guided refinement for 2D-to-3D human pose estimation,” in Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth Symposium on Educational Advances in Artificial Intelligence, vol. 37, article no. 144, 2023.
|
| [21] |
S. J. Yan, Y. J. Xiong, and D. H. Lin, “Spatial temporal graph convolutional networks for skeleton-based action recognition,” in Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence, article no. 912, 2018. (查阅网上资料, 未找到出版地, 请确认)
|
| [22] |
C. Wu, X. J. Wu, and J. Kittler, “Spatial residual layer and dense connection block enhanced spatial temporal graph convolutional network for skeleton-based action recognition,” in 2019 IEEE/CVF International Conference on Computer Vision Workshop, Seoul, Korea (South), 2019.
|
| [23] |
X. X. Ma, J. J. Su, C. Y. Wang, et al., “Context modeling in 3D human pose estimation: A unified perspective,” in Proceedings of the 2021 IEEE/CVF conference on computer vision and pattern recognition, Nashville, TN, USA, pp. 6238–6247, 2021.
|
| [24] |
J. Martinez, R. Hossain, J. Romero, et al., “A simple yet effective baseline for 3D human pose estimation,” in 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 2017.
|
| [25] |
D. Pavllo, C. Feichtenhofer, D. Grangier, et al., “3D human pose estimation in video with temporal convolutions and semi-supervised training,” in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 2020.
|
| [26] |
T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” in 5th International Conference on Learning Representations, Toulon, France, 2017.
|
| [27] |
J. L. Zhang, Z. G. Tu, J. Y. Yang, et al., “MixSTE: Seq2seq mixed spatio-temporal encoder for 3D human pose estimation in video,” in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 2022.
|
| [28] |
W. K. Shan, Z. H. Liu, X. F. Zhang, et al., “P-STMO: Pre-trained spatial temporal many-to-one model for 3D human pose estimation,” in 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022.
|
| [29] |
L. Shi, Y. F. Zhang, J. Cheng, et al., “Two-stream adaptive graph convolutional networks for skeleton-based action recognition,” in Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, pp. 12018–12027, 2019.
|
| [30] |
S. F. Wang, Y. J. Xin, D. H. Kong, et al., “Unsupervised learning of human pose distance metric via sparsity locality preserving projections,” IEEE Transactions on Multimedia, vol. 21, no. 2, pp. 314–327, 2019. doi: 10.1109/TMM.2018.2859029
|
| [31] |
Y. P. Wu, D. H. Kong, S. F. Wang, et al., “An unsupervised real-time framework of human pose tracking from range image sequences,” IEEE Transactions on Multimedia, vol. 22, no. 8, pp. 2177–2190, 2020. doi: 10.1109/TMM.2019.2953380
|
| [32] |
F. Yu and V. Koltun, “Multi-scale context aggregation by dilated convolutions,” in 4th International Conference on Learning Representations, San Juan, Puerto Rico, 2016.
|
| [33] |
H. Yang, D. Yan, L. Zhang, et al., “Feedback graph convolutional network for skeleton-based action recognition,” IEEE Transactions on Image Processing, vol. 31, pp. 164–175, 2022. doi: 10.1109/TIP.2021.3129117
|
| [34] |
C. Ionescu, D. Papava, V. Olaru, et al., “Human3.6m: Large scale datasets and predictive methods for 3D human sensing in natural environments,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 36, no. 7, pp. 1325–1339, 2014. doi: 10.1109/TPAMI.2013.248
|
| [35] |
X. P. Chen, K. Y. Lin, W. T. Liu, et al., “Weakly-supervised discovery of geometry-aware representation for 3D human pose estimation,” in Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, pp. 10887–10896, 2019.
|
| [36] |
D. Mehta, H. Rhodin, D. Casas, et al., “Monocular 3D human pose estimation in the wild using improved CNN supervision,” in 2017 international conference on 3D vision (3DV), Qingdao, China, pp. 506–516, 2017.
|
| [37] |
R. X. Liu, J. Shen, H. Wang, et al., “Attention mechanism exploits temporal contexts: Real-time 3D human pose reconstruction,” in Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, pp. 5063–5072, 2020.
|
| [38] |
D. Kingma and J. Ba, “Adam: A method for stochastic optimization,” in 3rd International Conference on Learning Representations, San Diego, CA, USA, 2015.
|
| [39] |
Y. L. Chen, Z. C. Wang, Y. X. Peng, et al., “Cascaded pyramid network for multi-person pose estimation,” in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 2018.
|
| [40] |
Y. P. Wu, D. H. Kong, S. F. Wang, et al., “Hpgcn: Hierarchical poselet-guided graph convolutional network for 3D pose estimation,” Neurocomputing, vol. 487, pp. 243–256, 2022. doi: 10.1016/J.NEUCOM.2021.11.007
|
| [41] |
H. Li, B. W. Shi, W. R. Dai, et al., “Hierarchical graph networks for 3D human pose estimation,” In 32nd British Machine Vision Conference 2021, Online, 2021.
|
| [42] |
H. S. Fang, Y. L. Xu, W. G. Wang, et al., “Learning pose grammar to encode human body configuration for 3D pose estimation,” in Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2018.
|
| [43] |
M. R. I. Hossain and J. J. Little, “Exploiting temporal information for 3D human pose estimation,” in Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, pp. 69–86, 2018.
|
| [44] |
Z. M. Zou and W. Tang, “Modulated graph convolutional network for 3D human pose estimation,” in Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, pp. 11477–11487, 2021.
|
| [45] |
H. Ci, C. Y. Wang, X. X. Ma, et al., “Optimizing network structure for 3D human pose estimation,” in Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), pp. 2262–2271, 2019.
|
| [46] |
R. A. Yeh, Y. T. Hu, and A. G. Schwing, “Chirality nets for human pose regression,” Proceedings of the 33rd International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 2019.
|
| [47] |
J. H. Lin and G. H. Lee, “Trajectory space factorization for deep video-based 3D human pose estimation,” arXiv preprint, arXiv: 1908.08289, 2019.
|
| [48] |
K. H. Gong, J. F. Zhang, and J. S. Feng, “PoseAug: A differentiable pose augmentation framework for 3D human pose estimation,” in Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, pp. 8571–8580, 2021.
|
| [49] |
J. W. Xu, Z. B. Yu, B. B. Ni, et al., “Deep kinematics analysis for monocular 3D human pose estimation,” in Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, pp. 896–905, 2020.
|
| [50] |
W. H. Li, H. Liu, R. W. Ding, et al., “Exploiting temporal contexts with strided transformer for 3D human pose estimation,” IEEE Transactions on Multimedia, vol. 25, pp. 1282–1293, 2022. doi: 10.1109/TMM.2022.3141231
|
| [51] |
D. Mehta, S. Sridhar, O. Sotnychenko, et al., “VNect: Real-time 3D human pose estimation with a single RGB camera,” ACM Transactions on Graphics, vol. 36, no. 4, article no. 44, 2017. doi: 10.1145/3072959.3073596
|

Figures(8) / Tables(7)

CJE QR CODE

CIE QR CODE
Copyright © Editorial Office of Chinese Journal of Electronics | 京ICP备12041980号-1 |
Supported by:
Beijing Renhe Information Technology Co. Ltd




 DownLoad:
DownLoad: