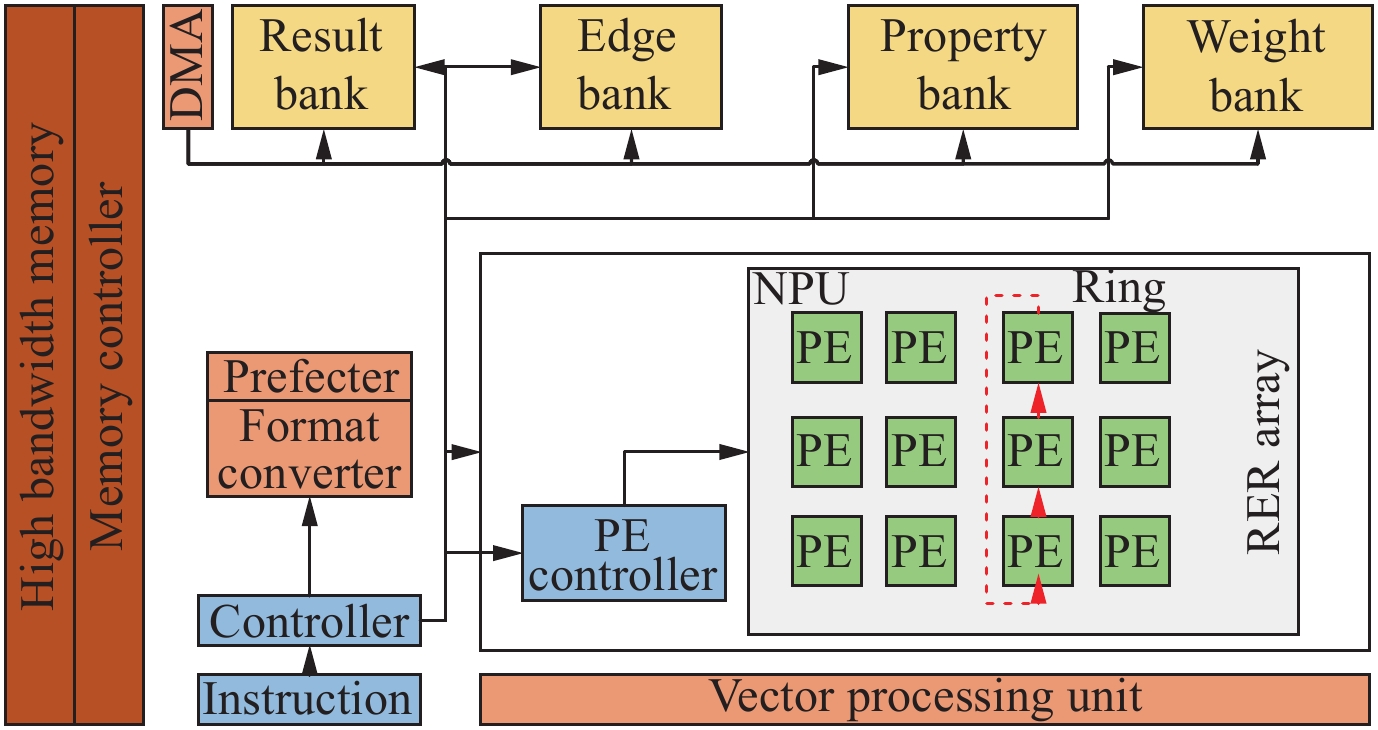
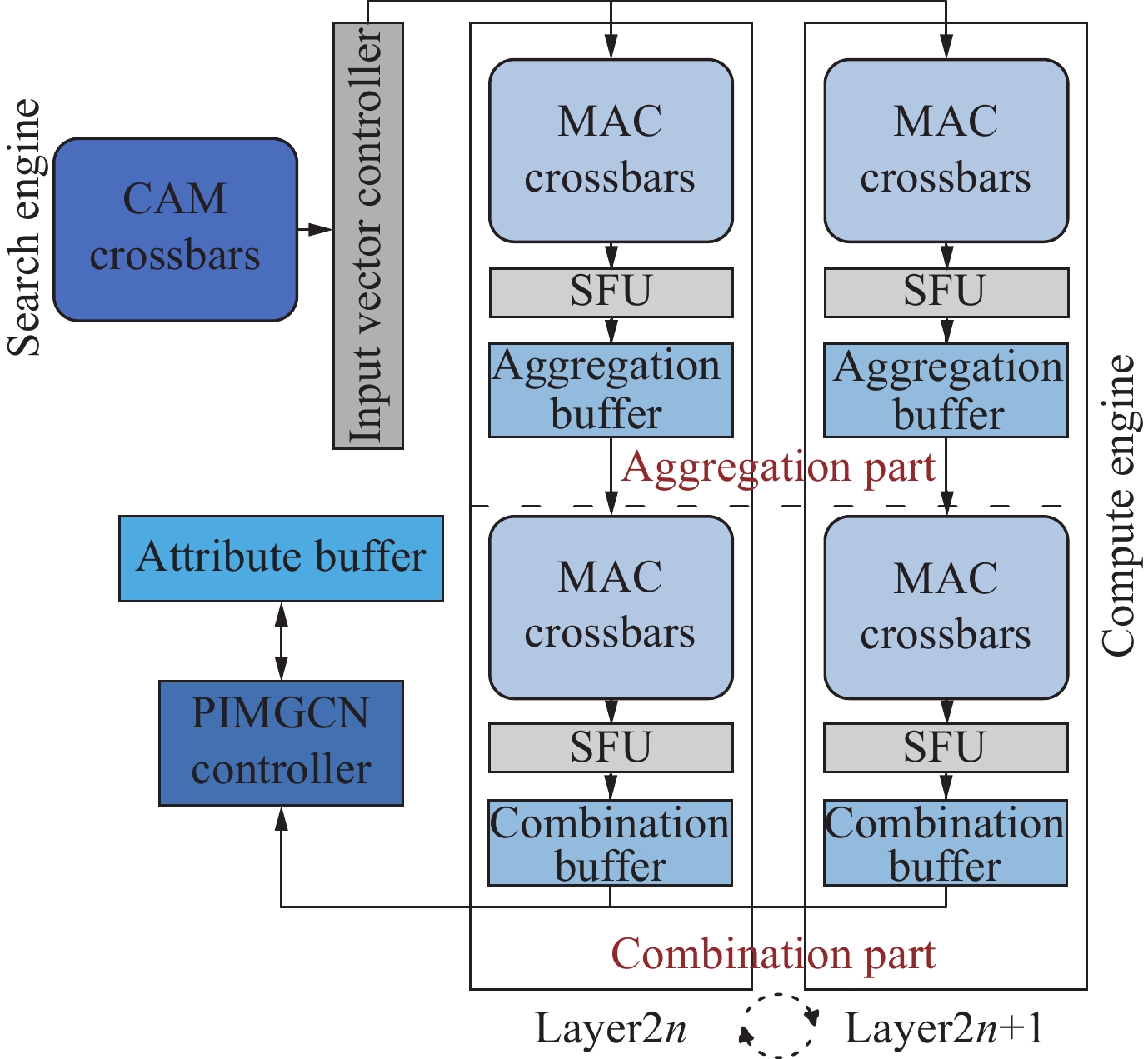
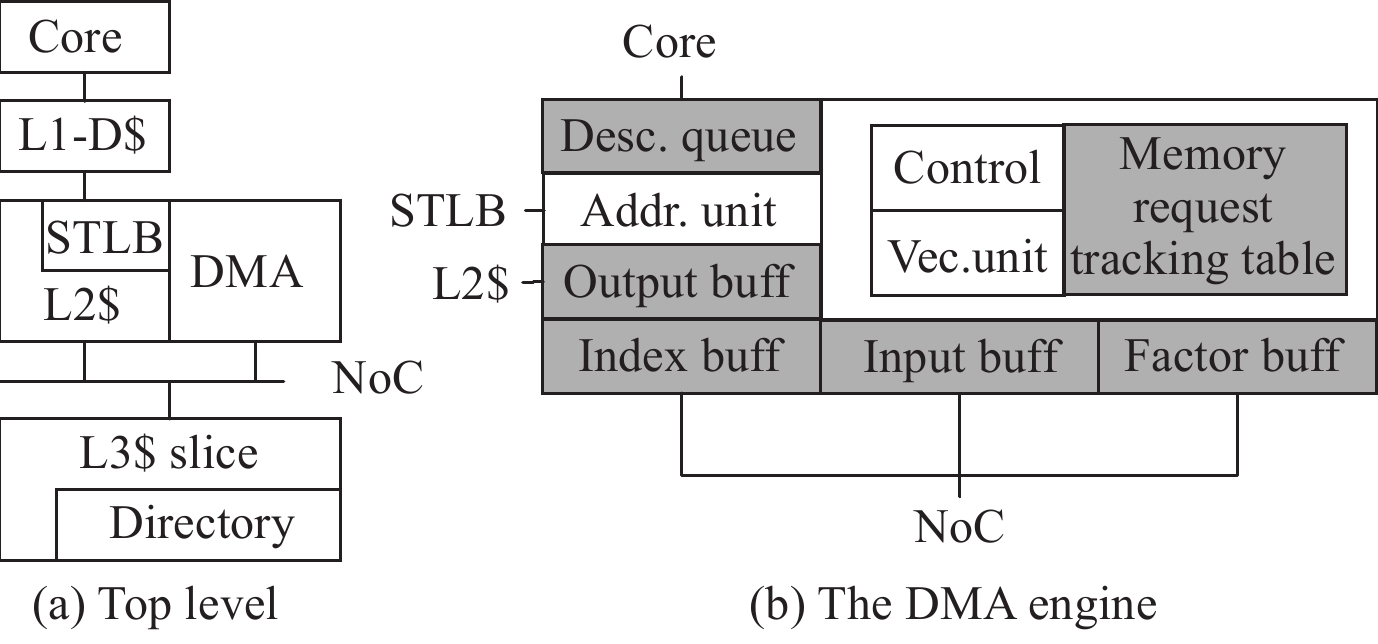
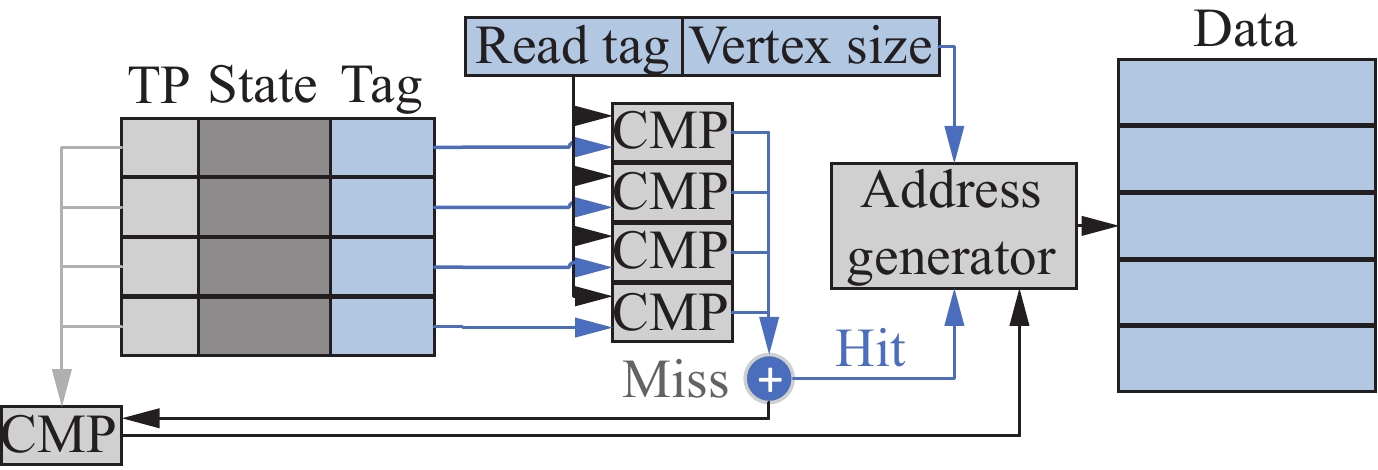
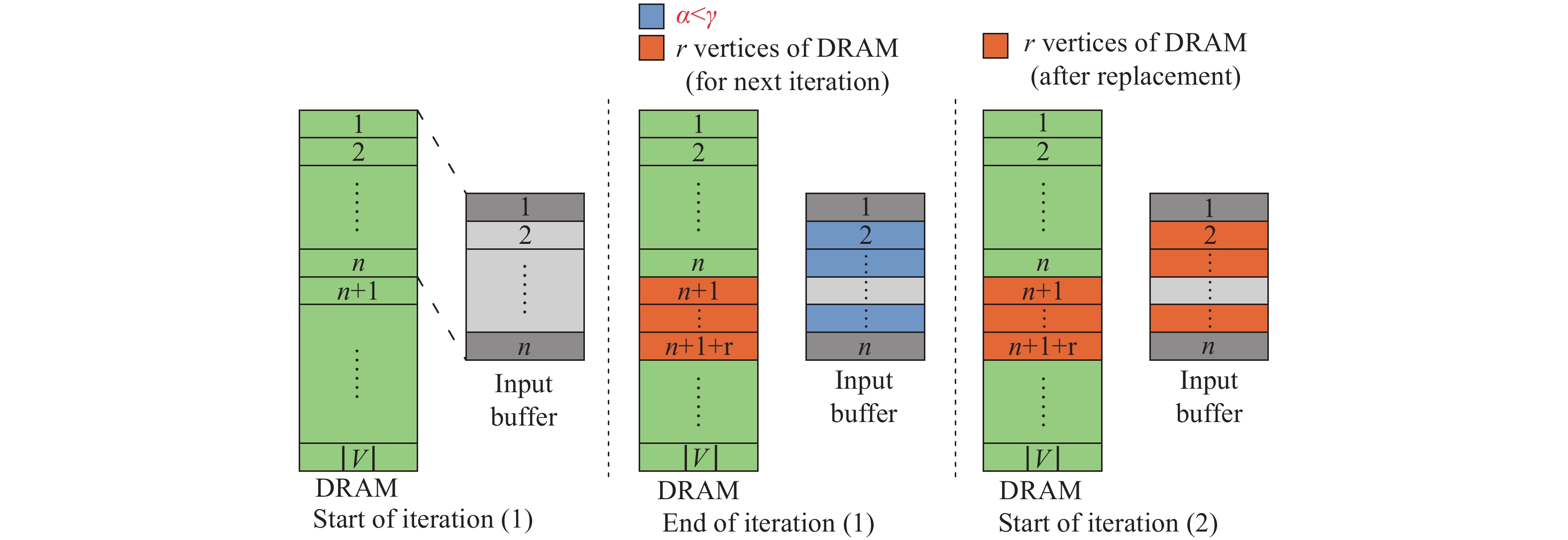
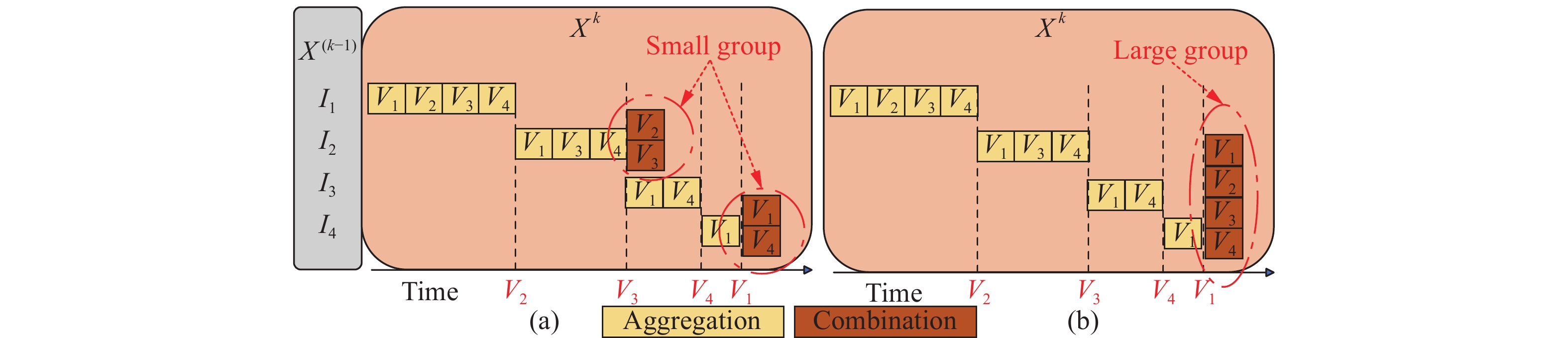
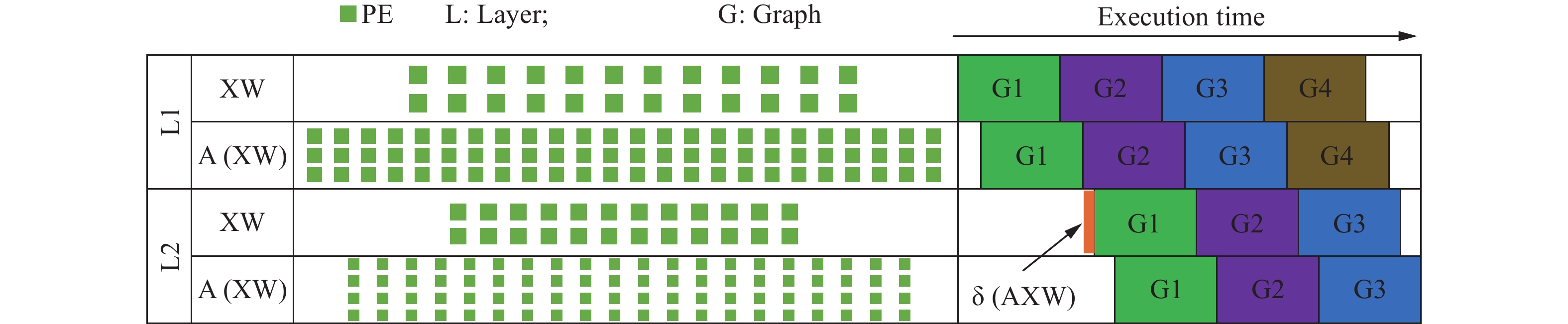
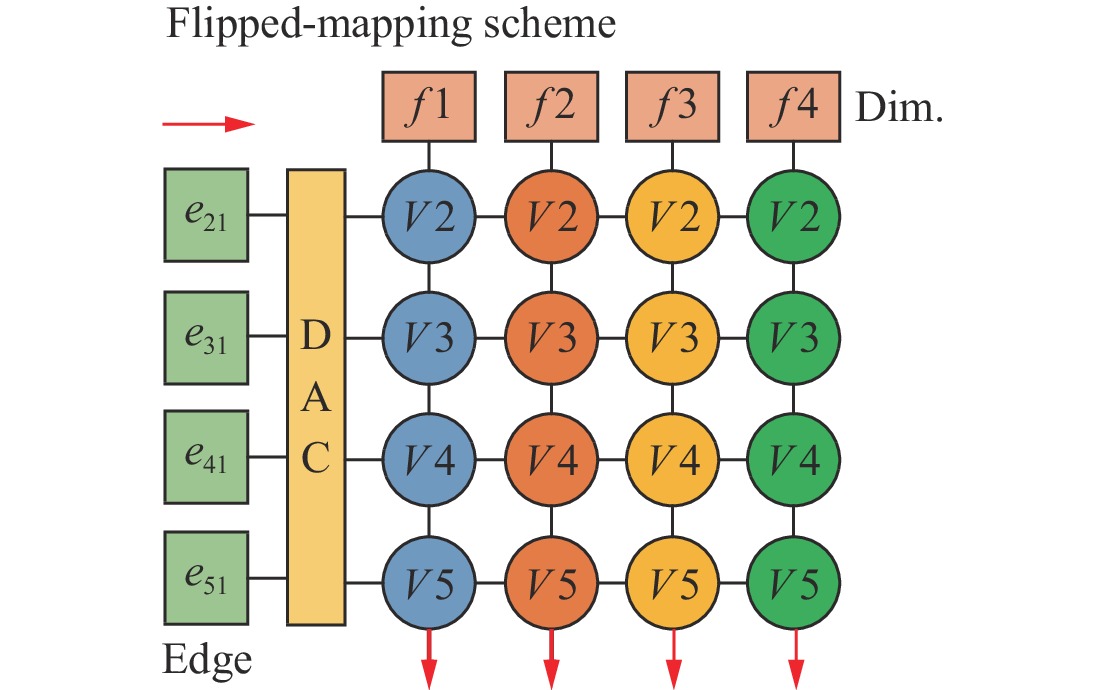
| Citation: | Shi CHEN, Jingyu LIU, and Li SHEN, “A Survey on Graph Neural Network Acceleration: A Hardware Perspective,” Chinese Journal of Electronics, vol. 33, no. 3, pp. 601–622, 2024 doi: 10.23919/cje.2023.00.135

|
| [1] |
W. L. Hamilton, R. Ying, and J. Leskovec, “Inductive representation learning on large graphs,” in Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, pp. 1025–1035, 2017.
|
| [2] |
T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” in Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 2017.
|
| [3] |
K. Xu, W. H. Hu, J. Leskovec, et al., “How powerful are graph neural networks?,” in Proceedings of the 7th International Conference on Learning Representations, New Orleans, LA, USA, 2019.
|
| [4] |
P. Veličković, G. Cucurull, A. Casanova, et al., “Graph attention networks,” in Proceedings of the 6th International Conference on Learning Representations, Vancouver, Canada, 2018.
|
| [5] |
R. Ying, D. Bourgeois, J. X. You, et al., “GNNExplainer: Generating explanations for graph neural networks,” in Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, Canada, article no. 829, 2019.
|
| [6] |
H. T. Nguyen, Q. D. Ngo, and V. H. Le, “IoT botnet detection approach based on PSI graph and DGCNN classifier,” in Proceedings of 2018 IEEE International Conference on Information Communication and Signal Processing (ICICSP), Singapore, pp. 118–122, 2018.
|
| [7] |
R. Zhu, K. Zhao, H. X. Yang, et al., “AliGraph: A comprehensive graph neural network platform,” Proceedings of the VLDB Endowment, vol. 12, no. 12, pp. 2094–2105, 2019. doi: 10.14778/3352063.3352127
|
| [8] |
T. Xie and J. C. Grossman, “Crystal graph convolutional neural networks for an accurate and interpretable prediction of material properties,” Physical Review Letters, vol. 120, no. 14, article no. 145301, 2018. doi: 10.1103/PhysRevLett.120.145301
|
| [9] |
M. Zitnik, M. Agrawal, and J. Leskovec, “Modeling polypharmacy side effects with graph convolutional networks,” Bioinformatics, vol. 34, no. 13, pp. i457–i466, 2018. doi: 10.1093/bioinformatics/bty294
|
| [10] |
C. W. Coley, W. G. Jin, L. Rogers, et al., “A graph-convolutional neural network model for the prediction of chemical reactivity,” Chemical Science, vol. 10, no. 2, pp. 370–377, 2019. doi: 10.1039/c8sc04228d
|
| [11] |
Y. X. Liu, N. Zhang, D. Wu, et al., “Guiding cascading failure search with interpretable graph convolutional network,” arXiv preprint, arXiv: 2001.11553, 2020.
|
| [12] |
J. Chen, T. F. Ma, and C. Xiao, “FastGCN: Fast learning with graph convolutional networks via importance sampling,” in Proceedings of the 6th International Conference on Learning Representations, Vancouver, Canada, 2018.
|
| [13] |
A. Bojchevski, J. Gasteiger, B. Perozzi, et al., “Scaling graph neural networks with approximate PageRank,” in Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, CA, USA, pp. 2464–2473, 2020.
|
| [14] |
M. Fey and J. E. Lenssen, “Fast graph representation learning with PyTorch geometric,” arXiv preprint, arXiv: 1903.02428, 2019.
|
| [15] |
M. J. Wang, D. Zheng, Z. H. Ye, et al., “Deep graph library: A graph-centric, highly-performant package for graph neural networks,” arXiv preprint, arXiv: 1909.01315, 2019.
|
| [16] |
Z. Q. Lin, C. Li, Y. S. Miao, et al., “PaGraph: Scaling GNN training on large graphs via computation-aware caching,” in Proceedings of the 11th ACM Symposium on Cloud Computing,Virtual Event, USA, pp. 401–415, 2020.
|
| [17] |
Q. X. Sun, Y. Liu, H. L. Yang, et al., “CoGNN: Efficient scheduling for concurrent GNN training on GPUs,” in Proceedings of SC22: International Conference for High Performance Computing, Networking, Storage and Analysis, Dallas, TX, USA, pp. 1–15, 2022.
|
| [18] |
Y. T. Gui, Y. D. Wu, H. Yang, et al., “HGL: Accelerating heterogeneous GNN training with holistic representation and optimization,” in Proceedings of SC22: International Conference for High Performance Computing, Networking, Storage and Analysis, Dallas, TX, USA, pp. 1–15, 2022.
|
| [19] |
A. Auten, M. Tomei, and R. Kumar, “Hardware acceleration of graph neural networks,” in Proceedings of 2020 57th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, pp. 1–6, 2020.
|
| [20] |
M. Y. Yan, Z. D. Chen, L. Deng, et al., “Characterizing and understanding GCNs on GPU,” IEEE Computer Architecture Letters, vol. 19, no. 1, pp. 22–25, 2020. doi: 10.1109/LCA.2020.2970395
|
| [21] |
M. Y. Yan, L. Deng, X. Hu, et al., “HyGCN: A GCN accelerator with hybrid architecture,” in Proceedings of 2020 IEEE International Symposium on High Performance Computer Architecture (HPCA), San Diego, CA, USA, pp. 15–29, 2020.
|
| [22] |
S. Q. Zhang, Z. Qin, Y. H. Yang, et al., “Transparent partial page migration between CPU and GPU,” Frontiers of Computer Science, vol. 14, no. 3, article no. 143101, 2020. doi: 10.1007/s11704-018-7386-4
|
| [23] |
S. J. Fan, J. W. Fei, and L. Shen, “Accelerating deep learning with a parallel mechanism using CPU + MIC,” International Journal of Parallel Programming, vol. 46, no. 4, pp. 660–673, 2018. doi: 10.1007/s10766-017-0535-9
|
| [24] |
T. Geng, A. Li, R. B. Shi, et al., “AWB-GCN: A graph convolutional network accelerator with runtime workload rebalancing,” in Proceedings of the 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Athens, Greece, pp. 922–936, 2020.
|
| [25] |
S. W. Liang, Y. Wang, C. Liu, et al., “EnGN: A high-throughput and energy-efficient accelerator for large graph neural networks,” IEEE Transactions on Computers, vol. 70, no. 9, pp. 1511–1525, 2021. doi: 10.1109/TC.2020.3014632
|
| [26] |
J. J. Li, A. Louri, A. Karanth, et al., “GCNAX: A flexible and energy-efficient accelerator for graph convolutional neural networks,” in Proceedings of 2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA), Seoul, Korea, pp. 775–788, 2021.
|
| [27] |
T. Yang, D. Y. Li, Y. B. Han, et al., “PIMGCN: A ReRAM-based PIM design for graph convolutional network acceleration,” in Proceedings of the 58th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, pp. 583–588, 2021.
|
| [28] |
T. Geng, C. S. Wu, Y. A. Zhang, et al., “I-GCN: A graph convolutional network accelerator with runtime locality enhancement through islandization,” in Proceedings of MICRO-54: 54th Annual IEEE/ACM International Symposium on Microarchitecture, Virtual Event, Greece, pp. 1051–1063, 2021.
|
| [29] |
H. R. You, T. Geng, Y. A. Zhang, et al., “GCoD: Graph convolutional network acceleration via dedicated algorithm and accelerator co-design,” in Proceedings of 2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA), Seoul, Korea, pp. 460–474, 2022.
|
| [30] |
X. Liu, M. Y. Yan, L. Deng, et al., “Survey on graph neural network acceleration: An algorithmic perspective,” in Proceedings of the 31st International Joint Conference on Artificial Intelligence, Vienna, Austria, pp. 5521–5529, 2022.
|
| [31] |
S. Abadal, A. Jain, R. Guirado, et al., “Computing graph neural networks: A survey from algorithms to accelerators,” ACM Computing Surveys, vol. 54, no. 9, article no. 191, 2021. doi: 10.1145/3477141
|
| [32] |
Z. H. Wu, S. R. Pan, F. W. Chen, et al., “A comprehensive survey on graph neural networks,” IEEE Transactions on Neural Networks and Learning Systems, vol. 32, no. 1, pp. 4–24, 2021. doi: 10.1109/TNNLS.2020.2978386
|
| [33] |
Z. Y. Liu and J. Zhou, “Graph convolutional networks,” in Introduction to Graph Neural Networks, Z. Y. Liu, J. Zhou, Eds. Springer, Cham, Switzerland, pp. 23–32, 2020.
|
| [34] |
Z. Y. Liu and J. Zhou, “Graph recurrent networks,” in Introduction to Graph Neural Networks, Z. Y. Liu, J. Zhou, Eds. Springer, Cham, Switzerland, pp. 33–37, 2020.
|
| [35] |
Z. T. Liu and J. Zhou, “Graph attention networks,” in Introduction to Graph Neural Networks, Z. Y. Liu, J. Zhou, Eds. Springer, Cham, Switzerland, pp. 39–41, 2020.
|
| [36] |
K. Cho, B. van Merrienboer, C. Gulcehre, et al., “Learning phrase representations using RNN encoder–decoder for statistical machine translation,” in Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, pp. 1724–1734, 2014.
|
| [37] |
S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997. doi: 10.1162/neco.1997.9.8.1735
|
| [38] |
M. Gori, G. Monfardini, and F. Scarselli, “A new model for learning in graph domains,” in Proceedings. 2005 IEEE International Joint Conference on Neural Networks, Montreal, Canada, pp. 729–734, 200.
|
| [39] |
L. Ruiz, F. Gama, and A. Ribeiro, “Gated graph recurrent neural networks,” IEEE Transactions on Signal Processing, vol. 68, pp. 6303–6318, 2020. doi: 10.1109/TSP.2020.3033962
|
| [40] |
R. Ying, J. X. You, C. Morris, et al., “Hierarchical graph representation learning with differentiable pooling,” in Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montréal, Canada, pp. 4805–4815, 2018.
|
| [41] |
J. Gilmer, S. S. Schoenholz, P. F. Riley, et al., “Neural message passing for quantum chemistry,” in Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, pp. 1263–1272, 2017.
|
| [42] |
Z. D. Chen, X. S. Li, and J. Bruna, “Supervised community detection with line graph neural networks,” in Proceedings of the 7th International Conference on Learning Representations, New Orleans, LA, USA, 2019.
|
| [43] |
G. H. Li, C. X. Xiong, A. Thabet, et al., “DeeperGCN: All you need to train deeper GCNs,” arXiv preprint, arXiv: 2006.07739, 2020.
|
| [44] |
X. Bresson and T. Laurent, “Residual gated graph ConvNets,” arXiv preprint, arXiv: 1711.07553, 2017.
|
| [45] |
M. Schlichtkrull, T. N. Kipf, P. Bloem, et al., “Modeling relational data with graph convolutional networks,” in Proceedings of the 15th European Semantic Web Conference, Heraklion, Crete, Greece, pp. 593–607, 2018.
|
| [46] |
Y. Wang, Y. B. Sun, Z. W. Liu, et al., “Dynamic graph CNN for learning on point clouds,” ACM Transactions on Graphics, vol. 38, no. 5, article no. 146, 2017. doi: 10.1145/3326362
|
| [47] |
Y. N. Dauphin, A. Fan, M. Auli, et al., “Language modeling with gated convolutional networks,” in Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, pp. 933–941, 2017.
|
| [48] |
J. X. You, R. Ying, X. Ren, et al., “GraphRNN: Generating realistic graphs with deep auto-regressive models,” in Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, pp. 5694–5703, 2018.
|
| [49] |
Y. J. Li, O. Vinyals, C. Dyer, et al., “Learning deep generative models of graphs,” arXiv preprint, arXiv: 1803.03324, 2018.
|
| [50] |
H. Y. Gao and S. W. Ji, “Graph u-nets,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 9, pp. 4948–4960, 2022. doi: 10.1109/TPAMI.2021.3081010
|
| [51] |
L. Zhao, Y. J. Song, C. Zhang, et al., “T-GCN: A temporal graph convolutional network for traffic prediction,” IEEE Transactions on Intelligent Transportation Systems, vol. 21, no. 9, pp. 3848–3858, 2020. doi: 10.1109/TITS.2019.2935152
|
| [52] |
G. Panagopoulos, G. Nikolentzos, and M. Vazirgiannis, “Transfer graph neural networks for pandemic forecasting,” in Proceedings of the 35th AAAI Conference on Artificial Intelligence, Virtual Event, USA, pp. 4838–4845, 2021.
|
| [53] |
H. Y. Gao, Z. Y. Wang, and S. W. Ji, “Large-scale learnable graph convolutional networks,” in Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, pp. 1416–1424, 2018.
|
| [54] |
W. L. Chiang, X. Q. Liu, S. Si, et al., “Cluster-GCN: An efficient algorithm for training deep and large graph convolutional networks,” in Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, pp. 257–266, 2019.
|
| [55] |
P. S. Huang, X. D. He, J. F. Gao, et al., “Learning deep structured semantic models for web search using clickthrough data,” in Proceedings of the 22nd ACM International Conference on Information & Knowledge Management, San Francisco, CA, USA, pp. 2333–2338, 2013.
|
| [56] |
N. P. Jouppi, C. Young, N. Patil, et al., “In-datacenter performance analysis of a tensor processing unit,” in Proceedings of the 44th Annual International Symposium on Computer Architecture, Toronto, Canada, pp. 1–12, 2017.
|
| [57] |
B. Y. Zhang, H. Q. Zeng, and V. Prasanna, “Hardware acceleration of large scale GCN inference,” in Proceedings of IEEE 31st International Conference on Application-specific Systems, Architectures and Processors (ASAP), Manchester, UK, pp. 61–68, 2020.
|
| [58] |
H. Q. Zeng and V. Prasanna, “GraphACT: Accelerating GCN training on CPU-FPGA heterogeneous platforms,” in Proceedings of the 2020 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Seaside, CA, USA, pp. 255–265, 2020.
|
| [59] |
C. Chen, K. L. Li, X. F. Zou, and Y. F. Li, “DyGNN: Algorithm and architecture support of dynamic pruning for graph neural networks,” in Proceedings of the 58th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, pp. 1201–1206, 2021.
|
| [60] |
J. R. Stevens, D. Das, S. Avancha, et al., “GNNerator: A hardware/software framework for accelerating graph neural networks,” in Proceedings of the 58th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, pp. 955–960, 2021.
|
| [61] |
C. Liu, H. K. Liu, H. Jin, et al., “ReGNN: A ReRAM-based heterogeneous architecture for general graph neural networks,” in Proceedings of the 59th ACM/IEEE Design Automation Conference, San Francisco, CA, USA, pp. 469–474, 2022.
|
| [62] |
J. X. Chen, Y. Q. Lin, K. Y. Sun, et al., “GCIM: Toward efficient processing of graph convolutional networks in 3d-stacked memory,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 41, no. 11, pp. 3579–3590, 2022. doi: 10.1109/TCAD.2022.3198320
|
| [63] |
C. Chen, K. L. Li, Y. F. Li, et al., “ReGNN: A redundancy-eliminated graph neural networks accelerator,” in Proceedings of 2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA), Seoul, Korea, pp. 429–443, 2022.
|
| [64] |
B. Y. Zhang, R. Kannan, and V. Prasanna, “BoostGCN: A framework for optimizing GCN inference on FPGA,” in Proceedings of 2021 IEEE 29th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Orlando, FL, USA, pp. 29–39, 2021.
|
| [65] |
S. W. Liang, C. Liu, Y. Wang, et al., “DeepBurning-GL: An automated framework for generating graph neural network accelerators,” in Proceedings of the 2020 IEEE/ACM International Conference on Computer Aided Design, San Diego, CA, USA, pp. 1–9, 2020.
|
| [66] |
Y. Zhu, Z. H. Zhu, G. H. Dai, et al., “Exploiting parallelism with vertex-clustering in processing-in-memory-based GCN accelerators,” in Proceedings of 2022 Design, Automation & Test in Europe Conference & Exhibition (DATE), Antwerp, Belgium, pp. 652–657, 2022.
|
| [67] |
C. M. Zhang, T. Geng, A. Q. Guo, et al., “H-GCN: A graph convolutional network accelerator on versal ACAP architecture,” in Proceedings of the 32nd International Conference on Field-Programmable Logic and Applications (FPL), Belfast, UK, pp. 200–208, 2022.
|
| [68] |
Y. C. Lin, B. Y. Zhang, and V. Prasanna, “HP-GNN: Generating high throughput GNN training implementation on CPU-FPGA heterogeneous platform,” in Proceedings of the 2022 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, pp. 123–133, 2022.
|
| [69] |
W. T. Hou, K. Zhong, S. L. Zeng, et al., “NTGAT: A graph attention network accelerator with runtime node tailoring,” in Proceedings of the 28th Asia and South Pacific Design Automation Conference, Tokyo, Japan, pp. 1–6, 2023.
|
| [70] |
X. K. Song, T. Zhi, Z. Fan, et al., “Cambricon-G: A polyvalent energy-efficient accelerator for dynamic graph neural networks,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 41, no. 1, pp. 116–128, 2022. doi: 10.1109/TCAD.2021.3052138
|
| [71] |
J. J. Li, H. Zheng, K. Wang, et al., “SGCNAX: A scalable graph convolutional neural network accelerator with workload balancing,” IEEE Transactions on Parallel and Distributed Systems, vol. 33, no. 11, pp. 2834–2845, 2022. doi: 10.1109/TPDS.2021.3133691
|
| [72] |
S. Mondal, S. D. Manasi, K. Kunal, et al., “GNNIE: GNN inference engine with load-balancing and graph-specific caching,” in Proceedings of the 59th ACM/IEEE Design Automation Conference, San Francisco, CA, USA, pp. 565–570, 2022.
|
| [73] |
Y. Huang, L. Zheng, P. C. Yao, et al., “Accelerating graph convolutional networks using crossbar-based processing-in-memory architectures,” in Proceedings of 2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA), Seoul, Korea, pp. 1029–1042, 2022.
|
| [74] |
Y. Huang, L. Zheng, P. C. Yao, et al., “ReaDy: A ReRAM-based processing-in-memory accelerator for dynamic graph convolutional networks,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 41, no. 11, pp. 3567–3578, 2022. doi: 10.1109/TCAD.2022.3199152
|
| [75] |
X. B. Chen, Y. K. Wang, X. F. Xie, et al., “Rubik: A hierarchical architecture for efficient graph neural network training,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 41, no. 4, pp. 936–949, 2022. doi: 10.1109/TCAD.2021.3079142
|
| [76] |
T. Yang, D. Y. Li, F. Ma, et al., “PASGCN: An ReRAM-based PIM design for GCN with adaptively sparsified graphs,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 42, no. 1, pp. 150–163, 2023. doi: 10.1109/TCAD.2022.3175031
|
| [77] |
C. Peltekis, D. Filippas, C. Nicopoulos, et al., “FusedGCN: A systolic three-matrix multiplication architecture for graph convolutional networks,” in Proceedings of IEEE 33rd International Conference on Application-specific Systems, Architectures and Processors (ASAP), Gothenburg, Sweden, pp. 93–97, 2022.
|
| [78] |
Y. A. Zhang, H. R. You, Y. G. Fu, et al., “G-CoS: GNN-accelerator co-search towards both better accuracy and efficiency,” in Proceedings of 2021 IEEE/ACM International Conference on Computer Aided Design (ICCAD), Munich, Germany, pp. 1–9, 2021.
|
| [79] |
Z. F. Tao, C. Wu, Y. Liang, et al., “LW-GCN: A lightweight FPGA-based graph convolutional network accelerator,” ACM Transactions on Reconfigurable Technology and Systems, vol. 16, no. 1, article no. 10, 2022. doi: 10.1145/3550075
|
| [80] |
A. I. Arka, B. K. Joardar, J. R. Doppa, et al., “DARE: Droplayer-aware manycore ReRAM architecture for training graph neural networks,” in Proceedings of 2021 IEEE/ACM International Conference On Computer Aided Design (ICCAD), Munich, Germany, pp. 1–9, 2021.
|
| [81] |
Z. X. W. Gong, H. X. Ji, Y. Yao, et al., “Graphite: Optimizing graph neural networks on CPUs through cooperative software-hardware techniques,” in Proceedings of the 49th Annual International Symposium on Computer Architecture, New York, NY, USA, pp. 916–931, 2022.
|
| [82] |
Y. Lee, J. Chung, and M. Rhu, “SmartSAGE: Training large-scale graph neural networks using in-storage processing architectures,” in Proceedings of the 49th Annual International Symposium on Computer Architecture, New York, NY, USA, pp. 932–945, 2022.
|
| [83] |
S. C. Li, D. M. Niu, Y. H. Wang, et al., “Hyperscale FPGA-as-a-service architecture for large-scale distributed graph neural network,” in Proceedings of the 49th Annual International Symposium on Computer Architecture, New York, NY, USA, pp. 946–961, 2022.
|
| [84] |
Z. Zhou, C. Li, X. C. Wei, et al., “GNNear: Accelerating full-batch training of graph neural networks with near-memory processing,” in Proceedings of the International Conference on Parallel Architectures and Compilation Techniques, Chicago, Illinois, pp. 54–68, 2022.
|
| [85] |
G. J. Sun, M. Y. Yan, D. Wang, et al., “Multi-node acceleration for large-scale GCNs,” IEEE Transactions on Computers, vol. 71, no. 12, pp. 3140–3152, 2022. doi: 10.1109/TC.2022.3207127
|
| [86] |
B. Gaide, D. Gaitonde, C. Ravishankar, et al., “Xilinx adaptive compute acceleration platform: VersalTM architecture,” in Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Seaside, CA, USA, pp. 84–93, 2019.
|
| [87] |
F. Manessi, A. Rozza, and M. Manzo, “Dynamic graph convolutional networks,” Pattern Recognition, vol. 97, article no. 107000, 2020. doi: 10.1016/j.patcog.2019.107000
|
| [88] |
N. Challapalle, S. Rampalli, L. H. Song, et al., “GaaS-X: Graph analytics accelerator supporting sparse data representation using crossbar architectures,” in Proceedings of ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), Valencia, Spain, pp. 433–445, 2020.
|
| [89] |
P. Chi, S. C. Li, C. Xu, et al., “PRIME: A novel processing-in-memory architecture for neural network computation in ReRAM-based main memory,” in Proceedings of ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), Seoul, Korea, pp. 27–39, 2016.
|
| [90] |
Y. Rong, W. B. Huang, T. Y. Xu, et al., “DropEdge: Towards deep graph convolutional networks on node classification,” in Proceedings of the 8th International Conference on Learning Representations, Addis Ababa, Ethiopia, pp. 1-17, 2019.
|
| [91] |
N. Srivastava, G. Hinton, A. Krizhevsky, et al., “Dropout: A simple way to prevent neural networks from overfitting,” The Journal of Machine Learning Research, vol. 15, no. 1, pp. 1929–1958, 2014.
|
| [92] |
N. P. Jouppi, D. H. Yoon, G. Kurian, et al., “A domain-specific supercomputer for training deep neural networks,” Communications of the ACM, vol. 63, no. 7, pp. 67–78, 2020. doi: 10.1145/3360307
|
| [93] |
Y. M. Zhang, V. Kiriansky, C. Mendis, et al., “Making caches work for graph analytics,” in Proceedings of 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, pp. 293–302, 2017.
|
| [94] |
X. W. Zhu, W. T. Han, and W. G. Chen, “GridGraph: Large-scale graph processing on a single machine using 2-level hierarchical partitioning,” in Proceedings of the 2015 USENIX Conference on Usenix Annual Technical Conference, Santa Clara, CA, USA, pp. 375–386, 2015.
|
| [95] |
C. Ogbogu, A. I. Arka, B. K. Joardar, et al., “Accelerating large-scale graph neural network training on crossbar diet,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 41, no. 11, pp. 3626–3637, 2022. doi: 10.1109/TCAD.2022.3197342
|
| [96] |
J. Frankle and M. Carbin, “The lottery ticket hypothesis: Finding sparse, trainable neural networks,” in Proceedings of the 7th International Conference on Learning Representations, New Orleans, LA, USA, pp. 1-42, 2019.
|
| [97] |
X. Y. Wang, Y. Ma, Y. Q. Wang, et al., “Traffic flow prediction via spatial temporal graph neural network,” in Proceedings of the Web Conference 2020, Taipei, China, pp. 1082–1092, 2020.
|
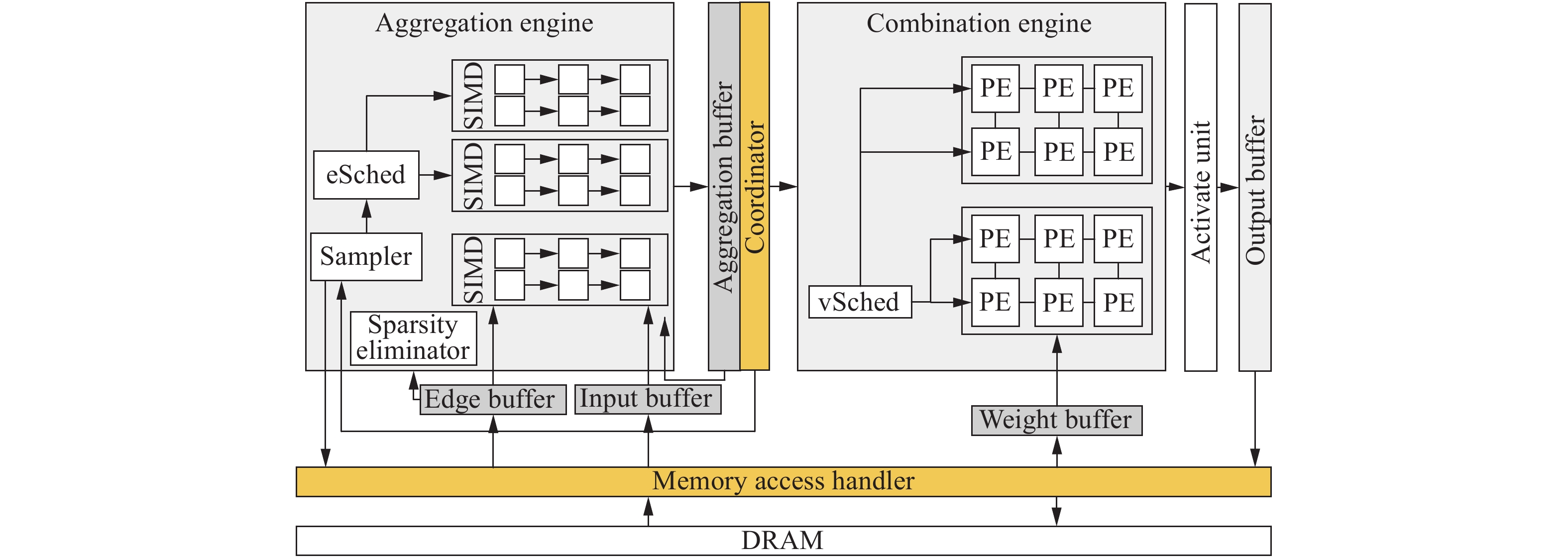
Figures(10) / Tables(5)

CJE QR CODE

CIE QR CODE
Copyright © Editorial Office of Chinese Journal of Electronics | 京ICP备12041980号-1 |
Supported by:
Beijing Renhe Information Technology Co. Ltd




 DownLoad:
DownLoad: