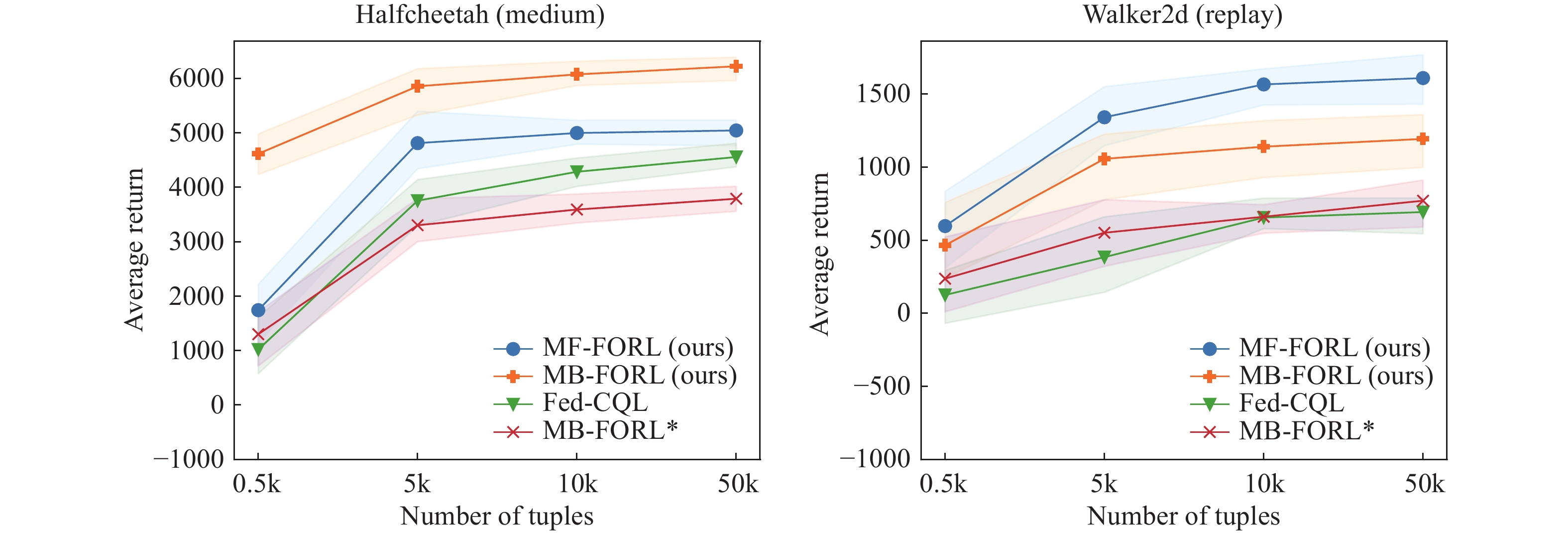
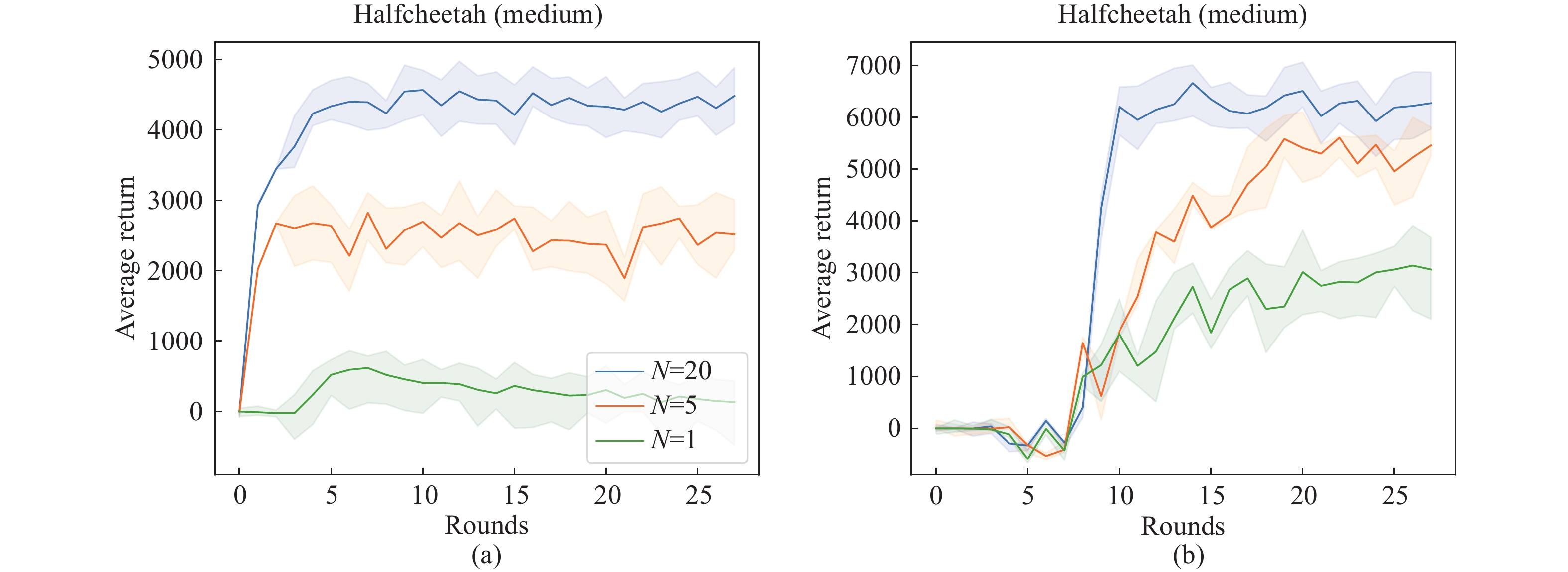
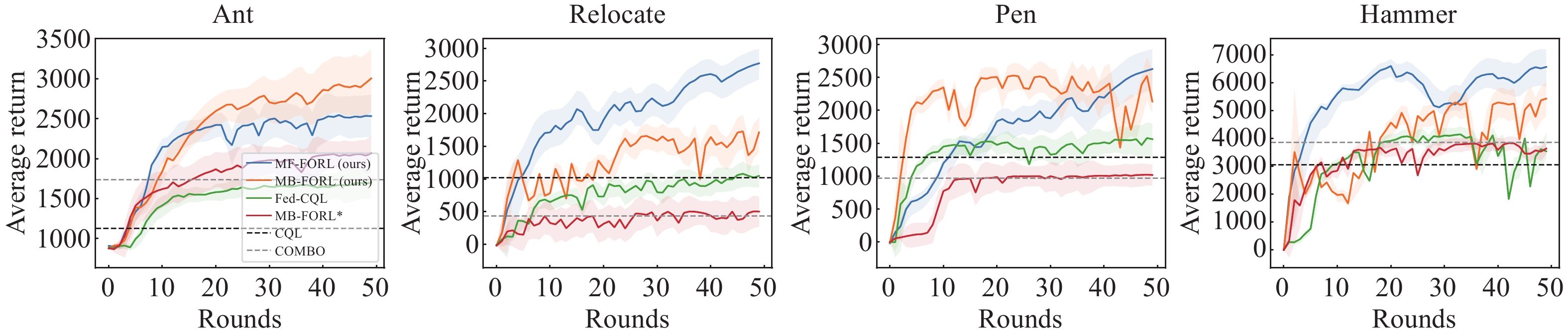
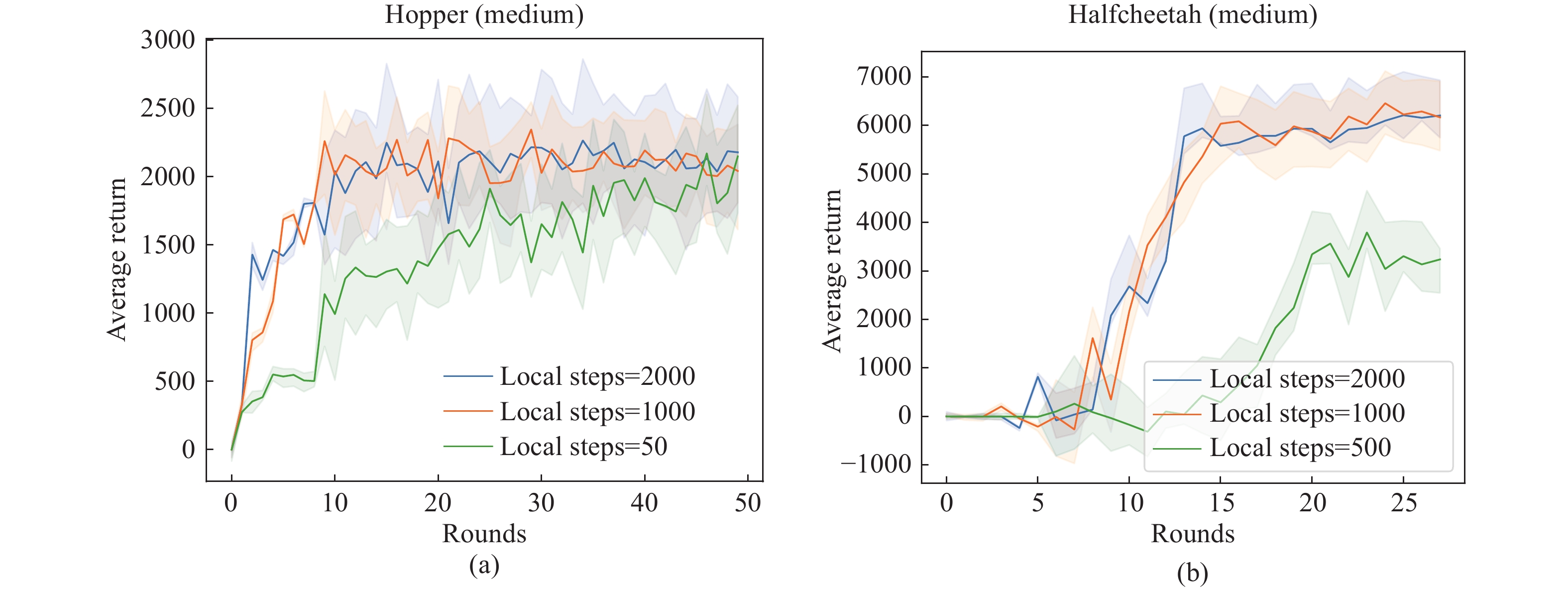
| Citation: | Sheng YUE, Yongheng DENG, Xingyuan HUA, et al., “Federated Offline Reinforcement Learning with Proximal Policy Evaluation,” Chinese Journal of Electronics, vol. x, no. x, pp. 1–14, xxxx doi: 10.23919/cje.2023.00.288

|
| [1] |
D. Kalashnikov, A. Irpan, P. Pastor, et al., “Scalable deep reinforcement learning for vision-based robotic manipulation,” in Proceedings of the 2nd Conference on Robot Learning, Zürich, Switzerland, pp. 651–673, 2018.
|
| [2] |
G. DeepMind, “AlphaStar: Mastering the real-time strategy game starcraft II,” Available at: https://deepmind.google/discover/blog/alphastar-mastering-the-real-time-strategy-game-starcraft-ii/, 2019-01-24.
|
| [3] |
L. H. Li, W. Chu, J. Langford, et al., “A contextual-bandit approach to personalized news article recommendation,” in Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, pp. 661–670, 2010.
|
| [4] |
P. S. Thomas, “Safe reinforcement learning,” Ph. D. Thesis, University of Massachusetts, MA, USA, 2015.
|
| [5] |
S. Levine, A. Kumar, G. Tucker, et al., “Offline reinforcement learning: Tutorial, review, and perspectives on open problems,” arXiv preprint, arXiv: 2005.01643, 2020.
|
| [6] |
A. Kumar, A. Zhou, G. Tucker, et al., “Conservative Q-learning for offline reinforcement learning,” in Proceedings of the 34th International Conference on Neural Information Processing Systems, Red Hook, NY, USA, article no. 100, 2020.
|
| [7] |
T. H. Yu, G. Thomas, L. T. Yu, et al., “MOPO: Model-based offline policy optimization,” in Proceedings of the 34th Conference on Neural Information Processing Systems, Online, pp. 14129–14142, 2020.
|
| [8] |
T. H. Yu, A. Kumar, R. Rafailov, et al., “COMBO: Conservative offline model-based policy optimization,” in Proceedings of the 35th Conference on Neural Information Processing Systems, Online, 2021.
|
| [9] |
D. Ghosh, A. Ajay, P. Agrawal, et al., “Offline RL policies should be trained to be adaptive,” in Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, pp. 7513–7530, 2022.
|
| [10] |
B. Trabucco, X. Y. Geng, A. Kumar, et al., “Design-bench: Benchmarks for data-driven offline model-based optimization,” in Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, pp. 21658–21676, 2022.
|
| [11] |
K. M. He, X. Y. Zhang, S. Q. Ren, et al., “Deep residual learning for image recognition,” in Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, pp. 770–778, 2016.
|
| [12] |
P. Rashidinejad, B. H. Zhu, C. Ma, et al., “Bridging offline reinforcement learning and imitation learning: A tale of pessimism,” in Proceedings of the 35th Conference on Neural Information Processing Systems, Online, pp. 11702–11716, 2021.
|
| [13] |
S. Fujimoto, D. Meger, and D. Precup, “Off-policy deep reinforcement learning without exploration,” in Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, pp. 2052–2062, 2019.
|
| [14] |
S. Lin, J. L. Wan, T. Y. Xu, et al., “Model-based offline meta-reinforcement learning with regularization,” in Proceedings of the Tenth International Conference on Learning Representations, Online, 2022.
|
| [15] |
P. Kairouz, H. B. McMahan, B. Avent, et al., “Advances and open problems in federated learning,” Foundations and Trends® in Machine Learning, vol. 14, no. 1-2, pp. 1–210, 2021. doi: 10.1561/2200000083
|
| [16] |
Z. Y. Du, C. Wu, T. Yoshinaga, et al., “Federated learning for vehicular internet of things: Recent advances and open issues,” IEEE Open Journal of the Computer Society, vol. 1, pp. 45–61, 2020. doi: 10.1109/OJCS.2020.2992630
|
| [17] |
X. H. Xu, H. Peng, L. C. Sun, et al., “FedMood: Federated learning on mobile health data for mood detection,” arXiv preprint, arXiv: 2102.09342, 2021.
|
| [18] |
D. Rengarajan, N. Ragothaman, D. Kalathil, et al., “Federated ensemble-directed offline reinforcement learning,” arXiv preprint, arXiv: 2305.03097, 2023.
|
| [19] |
A. Kumar, J. Fu, G. Tucker, et al., “Stabilizing off-policy Q-learning via bootstrapping error reduction,” in Proceedings of the 33rd Conference on Neural Information Processing Systems, Vancouver, Canada, 2019.
|
| [20] |
Y. F. Wu, G. Tucker, and O. Nachum, “Behavior regularized offline reinforcement learning,” arXiv preprint, arXiv: 1911.11361, 2019.
|
| [21] |
N. Jaques, A. Ghandeharioun, J. H. Shen, et al., “Way off-policy batch deep reinforcement learning of implicit human preferences in dialog,” arXiv preprint, arXiv: 1907.00456, 2019.
|
| [22] |
I. Kostrikov, R. Fergus, J. Tompson, et al., “Offline reinforcement learning with fisher divergence critic regularization,” in Proceedings of the 38th International Conference on Machine Learning, Online, pp. 5774–5783, 2021.
|
| [23] |
R. Kidambi, A. Rajeswaran, P. Netrapalli, et al., “MOReL: Model-based offline reinforcement learning,” in Proceedings of the 34th International Conference on Neural Information Processing Systems, Red Hook, NY, USA, article no. 1830, 2020.
|
| [24] |
C. Cang, A. Rajeswaran, P. Abbeel, et al., “Behavioral priors and dynamics models: Improving performance and domain transfer in offline RL,” arXiv preprint, arXiv: 2106.09119, 2021.
|
| [25] |
T. Matsushima, H. Furuta, Y. Matsuo, et al., “Deployment-efficient reinforcement learning via model-based offline optimization,” in Proceedings of the 9th International Conference on Learning Representations, Online, 2021.
|
| [26] |
T. Hishinuma and K. Senda, “Weighted model estimation for offline model-based reinforcement learning,” in Proceedings of the 35th Conference on Neural Information Processing Systems, Online, pp. 17789–17800, 2021.
|
| [27] |
R. Agarwal, D. Schuurmans, and M. Norouzi, “An optimistic perspective on offline reinforcement learning,” in Proceedings of the 37th International Conference on Machine Learning, Online, pp. 104–114, 2020.
|
| [28] |
N. Jiang and L. H. Li, “Doubly robust off-policy value evaluation for reinforcement learning,” in Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, pp. 652–661, 2016.
|
| [29] |
R. Y. Zhang, B. Dai, L. H. Li, et al., “GenDICE: Generalized offline estimation of stationary values,” in Proceedings of the 8th International Conference on Learning Representations, Addis Ababa, Ethiopia, 2020.
|
| [30] |
A. Sonabend-W, N. Laha, A. N. Ananthakrishnan, et al., “Semi-supervised off policy reinforcement learning,” arXiv preprint, arXiv: 2012.04809, 2021.
|
| [31] |
T. Y. Chen, K. Q. Zhang, G. B. Giannakis, et al., “Communication-efficient policy gradient methods for distributed reinforcement learning,” arXiv preprint, arXiv: 1812.03239, 2021.
|
| [32] |
L. Pan, L. B. Huang, T. Y. Ma, et al., “Plan better amid conservatism: Offline multi-agent reinforcement learning with actor rectification,” in Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, pp. 17221–17237, 2022.
|
| [33] |
C. Nadiger, A. Kumar, and S. Abdelhak, “Federated reinforcement learning for fast personalization,” in Proceedings of the 2019 IEEE Second International Conference on Artificial Intelligence and Knowledge Engineering, Sardinia, Italy, pp. 123–127, 2019.
|
| [34] |
A. Anwar and A. Raychowdhury, “Multi-task federated reinforcement learning with adversaries,” arXiv preprint, arXiv: 2103.06473, 2021.
|
| [35] |
B. Y. Liu, L. J. Wang, and M. Liu, “Lifelong federated reinforcement learning: A learning architecture for navigation in cloud robotic systems,” IEEE Robotics and Automation Letters, vol. 4, no. 4, pp. 4555–4562, 2019. doi: 10.1109/LRA.2019.2931179
|
| [36] |
H. K. Lim, J. B. Kim, J. S. Heo, et al., “Federated reinforcement learning for training control policies on multiple IoT devices,” Sensors, vol. 20, no. 5, article no. 1359, 2020. doi: 10.3390/s20051359
|
| [37] |
X. L. Liang, Y. Liu, T. J. Chen, et al., “Federated transfer reinforcement learning for autonomous driving,” arXiv preprint, arXiv: 1910.06001, 2019.
|
| [38] |
H. Cha, J. Park, H. Kim, et al., “Federated reinforcement distillation with proxy experience memory,” arXiv preprint, arXiv: 1907.06536, 2020.
|
| [39] |
A. A. Rusu, S. G. Colmenarejo, C. Gülçehre, et al., “Policy distillation,” in Proceedings of the 4th International Conference on Learning Representations, San Juan, Puerto Rico, 2016.
|
| [40] |
H. H. Zhuo, W. F. Feng, Y. F. Lin, et al., “Federated deep reinforcement learning,” arXiv preprint, arXiv: 1901.08277, 2020.
|
| [41] |
D. D. Zhou, Y. F. Zhang, A. Sonabend-W, et al., “Federated offline reinforcement learning,” arXiv preprint, arXiv: 2206.05581, 2024.
|
| [42] |
T. Li, A. K. Sahu, A. Talwalkar, et al., “Federated learning: Challenges, methods, and future directions,” IEEE Signal Processing Magazine, vol. 37, no. 3, pp. 50–60, 2020. doi: 10.1109/MSP.2020.2975749
|
| [43] |
T. Lin, L. J. Kong, S. U. Stich, et al., “Ensemble distillation for robust model fusion in federated learning,” in Proceedings of the 34th International Conference on Neural Information Processing Systems, Red Hook, NY, USA, article no. 198, 2020.
|
| [44] |
X. C. Li, J. L. Tang, S. M. Song, et al., “Avoid overfitting user specific information in federated keyword spotting,” arXiv preprint, arXiv: 2206.08864, 2022.
|
| [45] |
T. Li, A. K. Sahu, M. Zaheer, et al., “Federated optimization in heterogeneous networks,” in Proceedings of Machine Learning and Systems 2020, Austin, TX, USA, pp. 429–450, 2020.
|
| [46] |
B. McMahan, E. Moore, D. Ramage, et al., “Communication-efficient learning of deep networks from decentralized data,” in Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, pp. 1273–1282, 2017.
|
| [47] |
A. Reisizadeh, A. Mokhtari, H. Hassani, et al., “FedPAQ: A communication-efficient federated learning method with periodic averaging and quantization,” in Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, Palermo, Sicily, Italy, pp. 2021–2031, 2020.
|
| [48] |
J. Fu, A. Kumar, O. Nachum, et al., “D4RL: Datasets for deep data-driven reinforcement learning,” arXiv preprint, arXiv: 2004.07219, 2021.
|
| [49] |
E. Todorov, T. Erez, and Y. Tassa, “MuJoCo: A physics engine for model-based control,” in Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, pp. 5026–5033, 2012.
|
Figures(8) / Tables(5)

CJE QR CODE

CIE QR CODE
Copyright © Editorial Office of Chinese Journal of Electronics | 京ICP备12041980号-1 |
Supported by:
Beijing Renhe Information Technology Co. Ltd




 DownLoad:
DownLoad: