Fan Zhang, Qiming Xu, Wei Hu, et al., “EASA: fine-tuning SAM with edge attention and adapters for image manipulation localization,” Chinese Journal of Electronics, vol. x, no. x, pp. 1–9, xxxx. DOI: 10.23919/cje.2024.00.086
Citation:
Fan Zhang, Qiming Xu, Wei Hu, et al., “EASA: fine-tuning SAM with edge attention and adapters for image manipulation localization,” Chinese Journal of Electronics, vol. x, no. x, pp. 1–9, xxxx. DOI: 10.23919/cje.2024.00.086
Fan Zhang, Qiming Xu, Wei Hu, et al., “EASA: fine-tuning SAM with edge attention and adapters for image manipulation localization,” Chinese Journal of Electronics, vol. x, no. x, pp. 1–9, xxxx. DOI: 10.23919/cje.2024.00.086
Citation:
Fan Zhang, Qiming Xu, Wei Hu, et al., “EASA: fine-tuning SAM with edge attention and adapters for image manipulation localization,” Chinese Journal of Electronics, vol. x, no. x, pp. 1–9, xxxx. DOI: 10.23919/cje.2024.00.086
Zhang Fan: Fan Zhang received the B.E. degree in communication engineering from the Civil Aviation University of China, Tianjin, China, in 2002, the M.S. degree in signal and information processing from Beihang University, Beijing, China, in 2005, and the Ph.D. degree in signal and information processing from Institute of Electronics, Chinese Academy of Sciences, Beijing, China, in 2008. He is currently a Full Professor in Electronic and Information Engineering with the Beijing University of Chemical Technology, Beijing, China. His research interests are remote sensing image processing, high performance computing and artificial intelligence. (Email: zhangf@mail.buct.edu.cn)
Xu Qiming: Qiming Xu is currently pursuing a Master’s degree in Software Engineering at Beijing University of Chemical Technology, Beijing, China. He specializes in Computer Vision (CV). His work centers on the optimization and application of foundational visual models for enhancing image analysis and interpretation capabilities. (Email: xuqm@mail.buct.edu.cn)
Hu Wei: Wei Hu received the B.S. and M.S. degrees in computer science from the Dalian University of Science and Technology, Dalian, China, and the Ph.D. degree in computer science from the Tsinghua University, Beijing, China, in 1999, 2002, and 2006, respectively.He is currently an Associate Professor of computer science with the Beijing University of Chemical Technology, Beijing, China. His research interests include computer graphics, computational photography, and scientific visualization. (Email: huwei@mail.buct.edu.cn)
Ma Fei: Fei Ma received the B.S., M.S., and Ph.D. degrees in electronic and information engineering from the Beihang University, Beijing, China, in 2013, 2016, and 2020 respectively. From 2017 to 2018, he was a Research Fellow with Department of Electrical Engineering, McGill University, Montreal, Canada.He is currently a Full Associate Professor at the College of Information Science and Technology, Beijing University of Chemical Technology, Beijing, China. His research interests include synthetic aperture radar (SAR) image processing, machine learning, artificial intelligence, and target detection. (Email: mafei@mail.buct.edu.cn)
The Segment Anything Model (SAM) is gaining attention for various applications due to its success in precise segmentation and zero-shot inference across diverse datasets. The Image Manipulation Localization (IML) task, facing a lack of high-quality, diverse datasets, could benefit from SAM’s strong generalization ability. However, the unique nature of the IML task presents a significant challenge: the vast distributional disparity between IML data and conventional visual task data makes it seem implausible to effectively transfer a pretrained model like SAM to this task. Models typically either forget previous knowledge or fail to adapt to IML’s unique data distribution due to structural mismatches. To address this, we introduce the Edge-Attention SAM-Adapter (EASA), which overcomes catastrophic forgetting and effectively adapts to IML’s unique data distribution. Specifically, our EASA method mitigates the issue of catastrophic forgetting by employing adapter tuning strategy and designs a novel edge-attention branch effectively captures the subtle traces of edge manipulations in manipulated regions. In our experiments across six public datasets, our method significantly enhances performance in IML tasks compared to state-of-the-art methods, thus showcasing the potential of SAM in various downstream tasks previously considered challenging. The code is available at https://github.com/erliufashi/EASA-Method-Official-Repository.
The recently developed Segment Anything Model (SAM) [1] by Meta AI has become a hot topic in the field of image segmentation. Its ability to precisely segment objects of various sizes and perform few-shot or zero-shot inference based on diverse prompts is remarkable, a feat achieved through training on over a billion image data. This has generated considerable interest in its potential as a robust foundational model for segmentation, particularly for downstream tasks that suffer from a lack of high-quality datasets. Areas such as medical segmentation and remote sensing [2]–[11] are likely to benefit, with preliminary efforts to apply SAM in these fields already underway [12]–[15]. The scarcity of high-quality datasets is not only a challenge in the fields of medical and remote sensing segmentation, but also significantly impacts the Image Manipulation Localization (IML) task. Furthermore, IML data differ greatly from those of other visual tasks, making it uniquely challenging.
The IML task, a complex subset of segmentation tasks, is becoming increasingly important as digital manipulation tools improve, making it easier to create realistic forgeries [16]–[18], as shown in Figure 1. Despite advancements in deep learning, the effectiveness of these techniques is still limited by the lack of high-quality datasets. Efforts to mitigate data scarcity include synthesizing datasets, as seen in ManTra-Net [19] with 102,028 images, H-LSTM [20] with 65,000 images, and BusterNet [21] with 100,000 images. Additionally, approaches like MVSS++ [22] and EMT-Net [23] introduce edge supervision, while NCL [24], PCL [25], and CFL-Net [26] utilize contrastive learning to differentiate manipulated from authentic regions. However, task accuracy challenges persist due to the limited manipulation patterns in both public [27]–[32] and synthetic [19], [21], [33] datasets. Models struggle with real-world manipulated images, indicating the need for a model like SAM with strong few-shot or zero-shot learning capabilities.
Figure
1.
Manipulated images produced by different means of operation (copy-move, splicing, removal).
SAM leverages the extensive knowledge gained during its large-scale pretraining, showcasing remarkable transfer and generalization potential on challenging tasks. However, the significant differences in objectives between IML tasks and other visual tasks pose a formidable challenge. We have identified two critical aspects to optimize SAM’s performance for this task:
Firstly, simply applying SAM fine-tuning to all downstream tasks is not a cure-all. Fine-tuning SAM on IML tasks can cause significant gradient anomalies due to differences in training data, potentially disrupting the pretrained model’s parameters and leading to catastrophic forgetting. Therefore, a tailored fine-tuning approach is essential.
Secondly, additional training customizations specific to IML tasks are needed to address the distribution gap between upstream and downstream data. We introduce an edge supervision branch that captures manipulation traces at the edges of altered areas, helping the model differentiate between manipulated and non-manipulated regions by focusing on boundaries.
To address these challenges, we propose the Edge-Attention SAM-Adapter (EASA) fine-tuning method. First, we freeze the image encoder module and design various adapter modules, fine-tuning additional parameters equivalent to about 7.5% of the original parameter volume. This approach effectively avoids the catastrophic forgetting issue associated with complete model fine-tuning and reduces the heavy transfer burden. Second, we design an Edge Attention module inspired by attention mechanisms, which generates high-quality edge prediction probability distribution maps. This bridges the data distribution gap between upstream and downstream tasks, simplifying the learning process for the IML task.
The main contributions of this work are summarized as follows:
● Our proposed EASA method has successfully facilitated the transfer of SAM to the IML task by effectively overcoming the issue of catastrophic forgetting and adapting to the challenging, unique data distribution of IML.
● Experiments conducted on six public benchmark datasets have shown that our method achieves state-of-the-art performance in the IML task, demonstrating the potential of SAM in challenging downstream tasks with a lack of high-quality datasets.
II.
Method
In this section, we delve into the comprehensive process of transferring SAM to the task of Image Manipulation Localization. We start by describing our transfer pipeline, then proceed to describe two pivotal components of our approach: adapter modules and the Edge Attention Branch, respectively. Finally, we provide an in-depth overview of our training settings and details.
1
Transfer pipeline
Our overall goal is to transfer the pre-trained SAM to the IML task, leveraging its extensive pre-training on large-scale mask data to improve the accuracy of the IML task. To fully utilize the knowledge acquired by SAM during pre-training, we have made two key efforts in the design of our transfer pipeline. First, we limited the set of trainable parameters to minimize the risk of catastrophic forgetting. Second, we designed an improved transfer loss to accelerate the model’s adaptation. We have formally described the entire process of our transfer pipeline below.
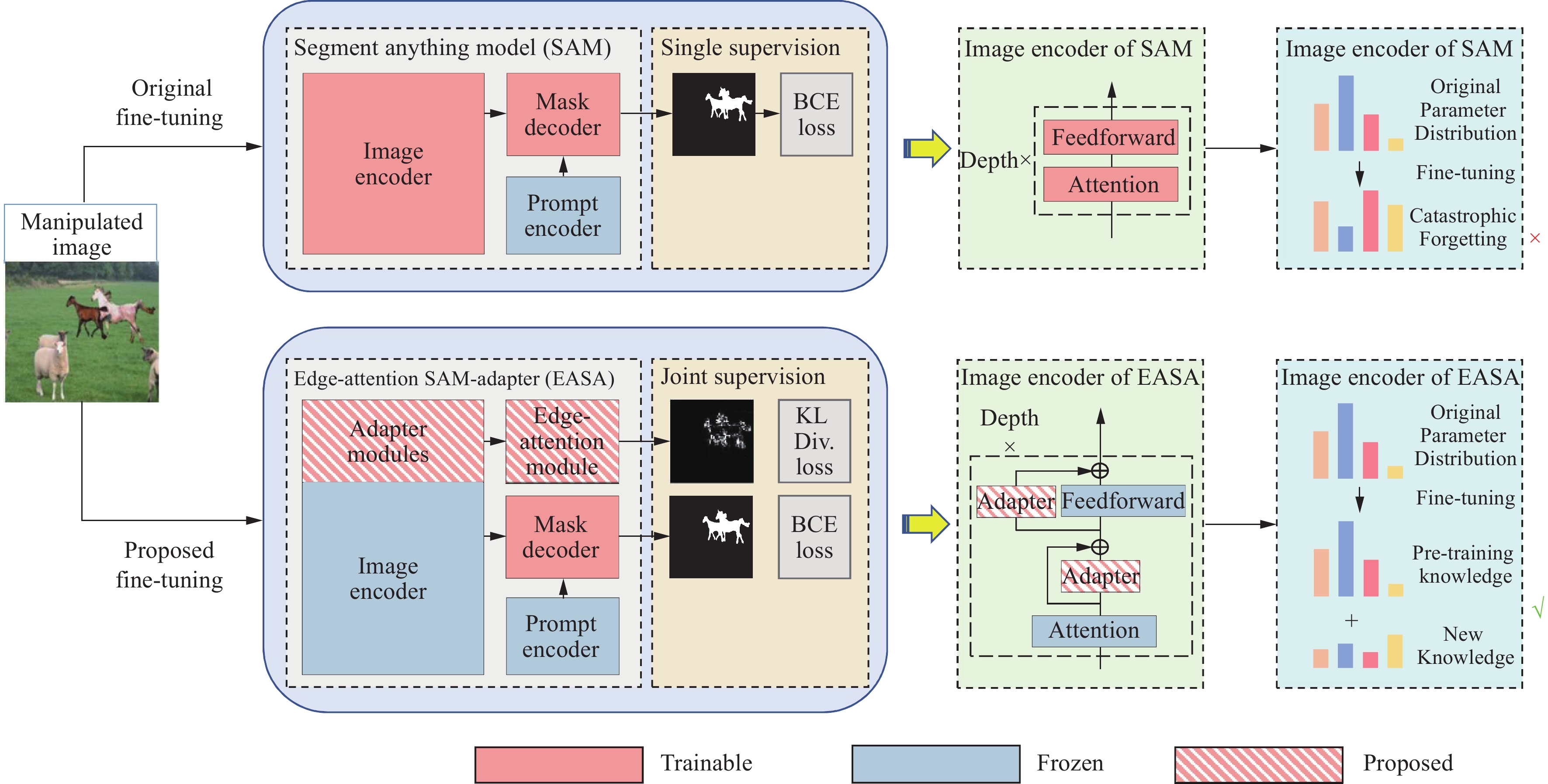
As demonstrated in Figure 2, the original architecture of SAM can be mathematically expressed as follows:
Figure
2.
The full process diagram of our proposed EASA method. The middle part shows the insertion points of the Edge Attention and adapter modules in SAM. For comparison, the original architecture of SAM is displayed in the top right corner.
where, Φi_enc,Φp_enc,Φm_dec represent the image encoder, prompt encoder, and mask decoder of the original model, respectively. Fimg denotes the features extracted from the input image, Tprompt represents the prompt word embeddings encoded from the input prompts, and M signifies the final output of the model.
Typically, the paradigm of transferring a foundation model to downstream tasks comprises two stages: pretraining and fine-tuning. The source domain Ds represents the domain where the foundation model is pretrained, covering general image understanding tasks. The target domain Dt signifies the downstream tasks. Originally, the foundation model was trained on Ds to obtain a model Φ(⋅,θ0) with parameters θ0. Subsequently, it is retrained in the target domain to adapt to downstream tasks.
In our task, the foundation model SAM consists of three sets of parameters trained on the source domain Ds, denoted as: Φi_enc(⋅,θi), Φp_enc(⋅,θp), Φm_dec(⋅,θm), where θi,θp,θm∈RD. And we define the target domain, IML tasks, as DIML.
In the process of transitioning SAM from the source domain to align with the target domain DIML, our approach is as follows. For the image encoder, we freeze its parameters and train an additional set of parameters. For the prompt encoder, we directly obtain the prompt word embeddings Tprompt. For the mask decoder, we apply a full-scale fine-tuning.
The fine-tuning process for the mask decoder can be described as follows:
θm_IML←argminθmL(θm,DIML),
(4)
where, L represents the loss function corresponding to the IML tasks, and θm_IML represents the target parameters we aim to obtain through fine-tuning.
For the image encoder, let us define an additional set of parameters Δθi∈Rd,d≪D. The fine-tuning process for the image encoder can then be described as:
Δθi_IML←argminΔθiL(Δθi,θi,DIML)
(5)
Concluding the transfer phase, the inference process of our SAM model on IML can be articulated as follows:
Fimg=Φi_enc(I,Δθi_IML,θi),
(6)
Tprompt=Φp_enc({p}),
(7)
M=Φm_dec(Fimg,Tprompt,θm_IML)
(8)
The above process introduces the ultimate goal of our fine-tuning SAM and shows our strategy for choosing fine-tuning components. Figure 2 shows all the trainable and untrainable modules in our method.
2
Adapter modules
Our belief is that SAM’s full potential is not realized in downstream tasks primarily due to the difference in data distributions between upstream and downstream datasets, which leading to unstable updates in the model’s parameters. It is crucial to keep SAM’s original parameters unchanged during training to ensure a smooth transition to IML tasks. With these considerations in mind, we have chosen the adapter tuning method. This method is specifically selected to both prevent catastrophic forgetting and to lower computational costs during the process of adapting SAM for IML tasks.
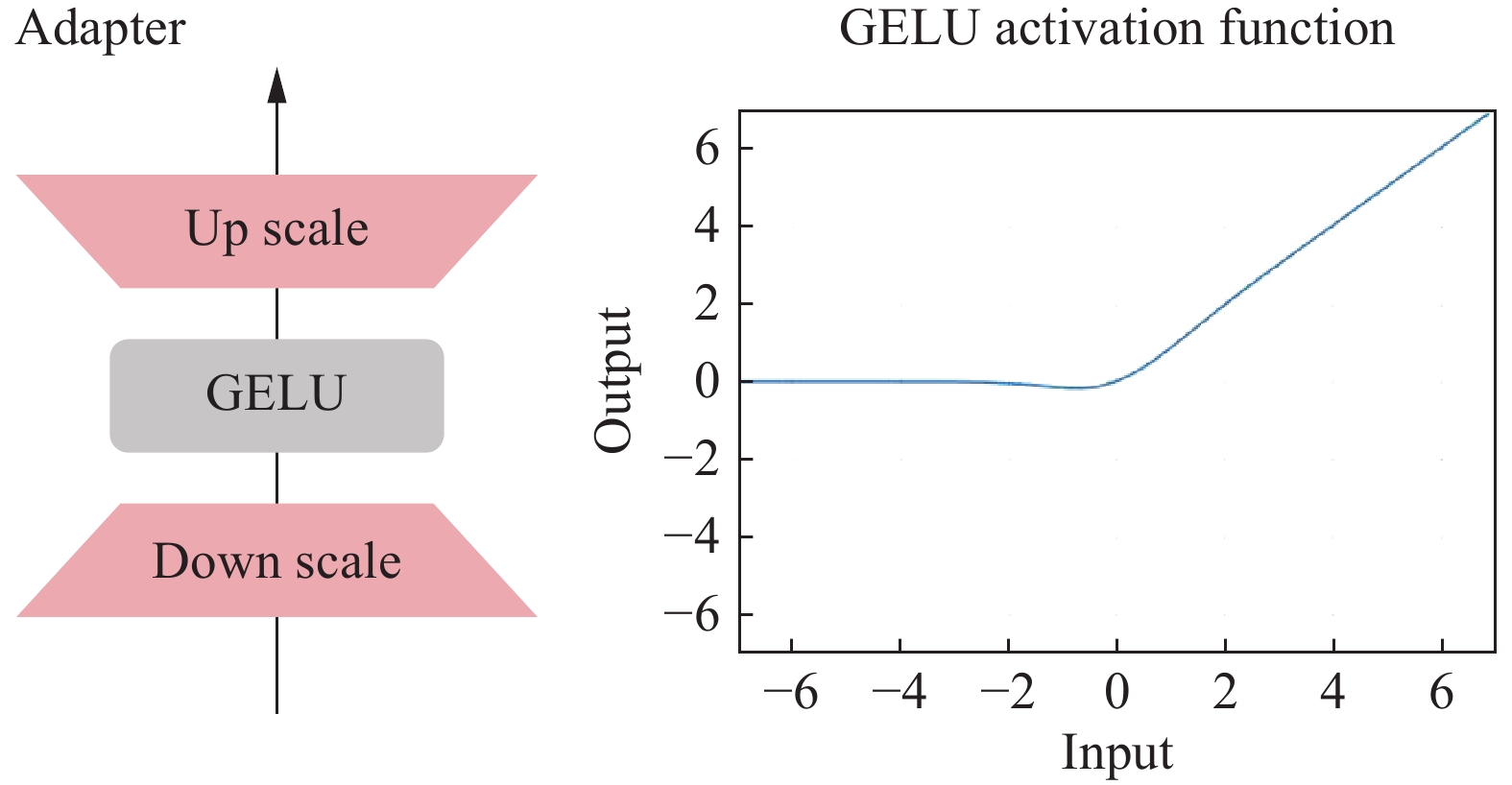
As shown in Figure 3, The adapter is a bottleneck model that sequentially uses downward projection, an activation function, and upward projection. The Formulated Description, the adapter can be defined as follows:
Figure
3.
The adapter is a bottleneck model that sequentially uses downward projection, an activation function, specifically the Gaussian Error Linear Unit (GELU), and upward projection.
where f(⋅) is a nonlinear activation function, and WDown∈Rr×d and WUp∈Rr×d are the down-projection and up-projection weight matrices respectively, x,y∈RN×d represents the model’s input and output hidden state, the adapter modules incorporate minimal additional parameters to the original model, allowing for task-specific learning.
As shown in Figure 3, we use the Gaussian Error Linear Unit (GELU) as our nonlinear activation function. The GELU is defined as:
f(x)=0.5x(1+tanh(√2/π(x+0.044715x3)))
(10)
Integrating GELU, the transformation in the adapter layer becomes:
h=GELU(h⋅Wdown)Wup
(11)
Adopting the GELU activation function maintains consistency with SAM’s module design, thereby facilitating smoother and more efficient learning during transfer.
In the SAM encoder, we deploy two adapter modules for each ViT block. For each standard ViT block, we have placed the first adapter after the multi-head attention layer and then placed the second adapter in parallel with the MLP layer, as shown in Figure 2.
Our fine-tuning approach for SAM’s image encoder with adapter modules presents two key benefits: enhanced computational efficiency and mitigation of catastrophic forgetting. By largely maintaining the pretrained model’s parameters, adapter tuning safeguards the model’s existing knowledge, crucial for consistent segmentation performance.
3
Edge Attention Branch
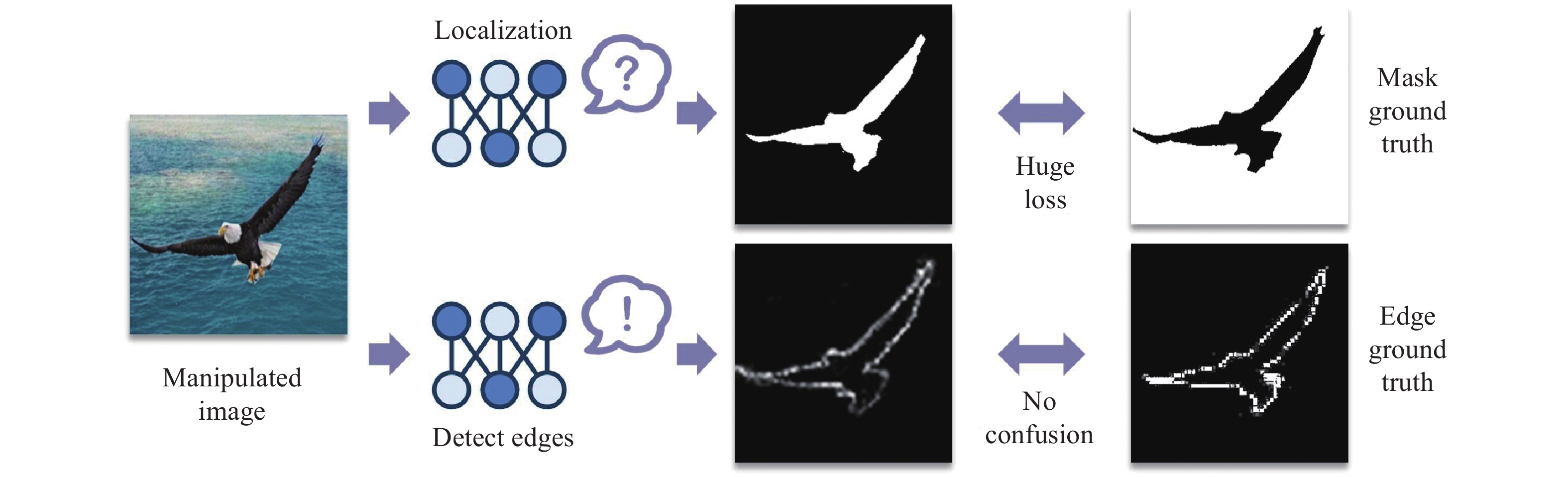
Solely relying on adapter fine-tuning falls short in bridging the data distribution and task disparity gaps between upstream and downstream tasks when transferring SAM. To enhance SAM’s fine-tuning process, we introduce an Edge Attention Branch, equipped with an edge attention module and an edge prediction loss function. This branch focuses on traces of manipulation typically found at the edges of altered regions, helping to pinpoint these areas with greater accuracy. It also tackles the challenge of differentiating between manipulated and unmanipulated sections, particularly in splice operations where such distinctions can be unclear, thus potentially leading to considerable fine-tuning losses. By treating the edges of manipulation regions as the definitive ground truth, the model shifts its focus to identifying boundary probabilities instead of classifying each segment, simplifying the task and reducing ambiguity, as illustrated in Figure 4.
Figure
4.
Examples of extreme cases where the network might completely misjudge the positive (manipulated) areas, resulting in significant loss fluctuations.
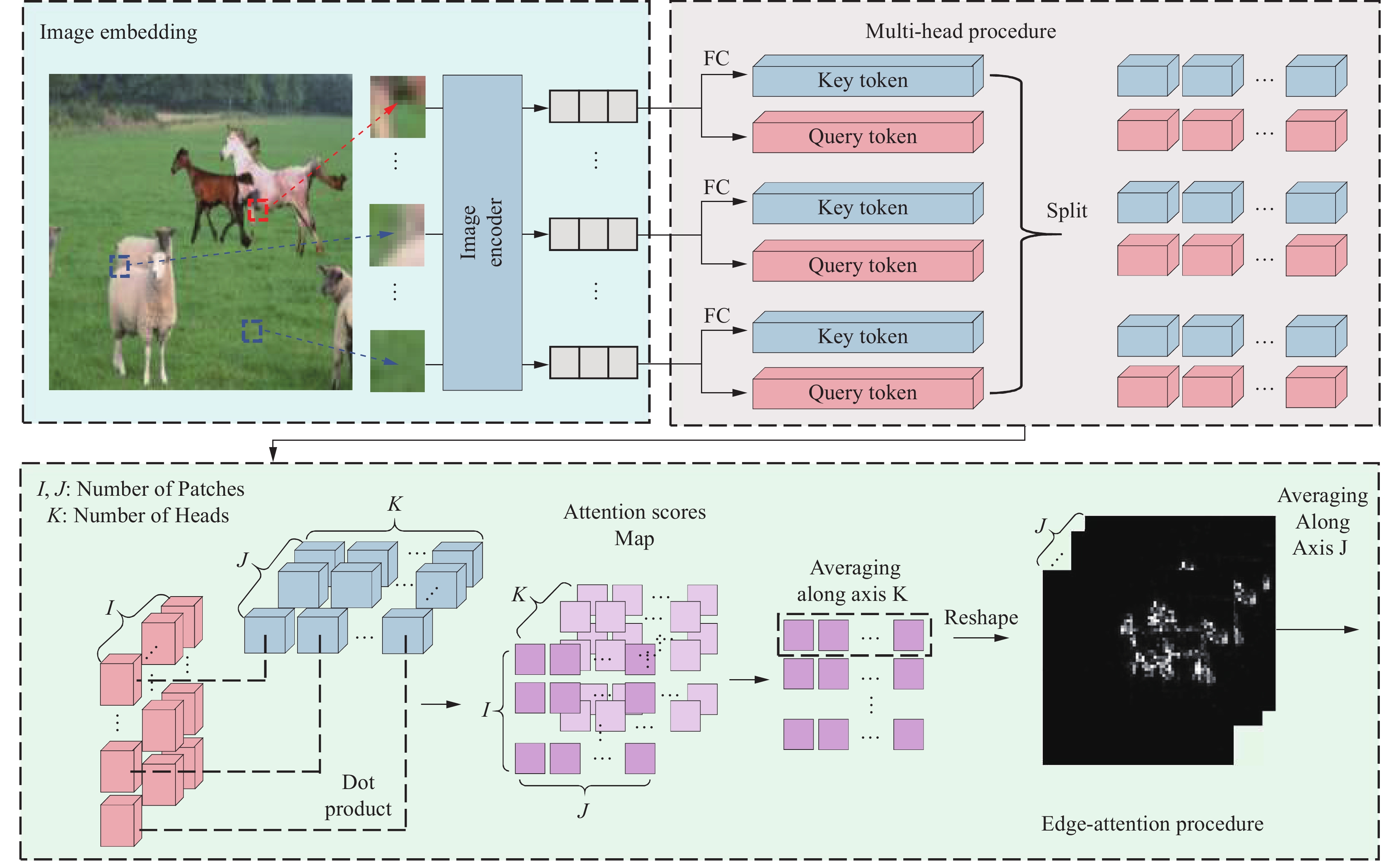
Our edge-attention module, inspired by visual transformers, represents boundary predictions as a probability graph across the image to better capture edge manipulations, shown in Figure 5.
Figure
5.
The complete process of the Edge Attention module generating probability maps for the edges of manipulated areas. The meaning of Key Tokens and Query Tokens, as well as the operations for generating attention scores, are identical to those in conventional attention mechanisms.
First, we generate query tokens Q∈Rn×d and key tokens K∈Rn×d, from the embedded vectors output by the image encoder through two fully connected layers:
Q=EWQ,K=EWK,
(12)
where E∈Rn×d denotes the embedded vectors from the image encoder, n is the number of tokens, d is the dimension of each token, and WQ,WK∈Rd×d are the weight matrices of the fully connected layers.
Specifically, the single-head implementation of this process can be described as:
Scores(Q,K)=Softmax(QKT√dk)
(13)
As illustrated, this process is akin to contrastive learning. To elaborate, we calculate positive and negative sample pairs as follows:
Positiveir:QjKTmanip>0,
(14)
NegativePair:QjKTnon-manip<0,
(15)
where, Qj represents j-th query token, Kmanip∈Rd is the key token associated with the manipulation area, and Knon-manip∈Rd is the key token associated with the non-manipulation area. This helps the model learn to capture anomalous features at the manipulation edges through this contrastive process.
In our actual implementation, we choose to apply multihead attention to enhance its effectiveness. The multi-head process can be described as follows:
Qi,j=QjWQi,
(16)
Ki=KWKi,
(17)
where i represents different heads, j represents tokens associated with different embedding vectors, Qi,j∈Rd are the query token for the i-th head and j-th token, and Ki∈Rn×d are the key tokens for the i-th head. WQi,WKi∈Rd×d are the weight matrices specific to each head.
Then, for each head in each query token, we calculate its score:
Scoresi,j=Qi,jKTi√dk
(18)
Next, we average the attention maps obtained from all query tokens to comprehensively consider the perspectives of all positional query tokens:
AvgScores=1h⋅qh∑i=1q∑j=1Scoresi,j
(19)
Finally, we apply the Softmax activation function to the obtained average score map:
FinalScores=Softmax(AvgScores)
(20)
In this way, we can effectively identify and emphasize anomalous features at the manipulation boundaries of the image. Now, all we need is the module’s corresponding edge prediction loss function.
2
Edge Prediction Loss Function
In segmentation, a widely used loss function is BCELoss. However, applying BCELoss to our edge-focused branch might present difficulties in parameter setting. This is due to the extreme imbalance between positive and negative samples from the perspective of edge prediction, which complicates the adjustment of the position weight parameter.
Considering that we have already obtained the probability distribution map of edge prediction as an output, the KL Divergence Loss function, which measures the cross entropy between two probability distribution systems, seems to be an excellent choice.
KL divergence loss function can be described as:
KLDivLoss=1NN∑i=1yi(log(yi)−log(fsi)),
(21)
where, N is the number of patches the image is split into, fs is FinalScores∈[0,1], defined in Equation 20, represents the output of the edge attention branch, y∈{0,1} is the true label.
Using the resulting edge probability distribution maps and its corresponding edge prediction loss function, we provide the model with an improved edge prediction view for IML. However, to balance the additional edge prediction loss incurred by this new view and to optimally coordinate the training of all trainable parameter sets, a more scientific training setup is essential.
4
Training Strategies
1
Dual-branch loss function
EASA adopts a dual-branch loss structure, accepting joint supervision from mask prediction loss and edge prediction loss. Our loss can be described as follows:
L=BCELoss+β×KLDivLoss,
(22)
where BCELoss represents the loss of mask prediction, described as follows:
BCELoss=−w×y×log(σ(x))+(1−y)×log(1−σ(x)),
(23)
where y is the true sample label, y∈{0,1}, x is the logits output by the mask decoder, w is the class loss weight for positive samples, and σ(x) is the sigmoid function:
σ(x)=11+e−x
(24)
2
Weight setting
Based on the effect of the model training on the Defacto validation set, we set w to 5, and β to 0.2.
III.
Experiments
1
Dataset and Evaluation
In our experimental framework, we strategically employed one training dataset alongside six test datasets, mirroring the setup used in the MVSS++ [22] benchmark to ensure consistency and facilitate a fair comparison of our results. We conducted training on the CASIAv2 [28] dataset and perform tests on the NIST16 [27], Columbia [32], CASIAv1 [31], COVERAGE [30], IMD2020 [29], and DEF-12k [22], [33] datasets, as shown in Table 1.
Table
1.
Seven Public Datasets. Our training and evaluation processes use only manipulated data.
In general, our experiments used one training dataset and six test datasets. The abbreviations used in Table 1 refer to different types of image manipulation techniques: “Mani.” stands for manipulated, “Spl.” stands for splicing, “CM.” stands for copy-move, and “Rmv.” stands for removal.
2
Implementation Details
All experiments were based on the vit-b version of SAM. We chose to freeze all parameters of the model’s image encoder and prompt encoder, and then fully fine-tune the mask decoder, edge attention module, and all adapter parameters.
EASA was implemented in PyTorch and trained on an NVIDIA RTX A5000 GPU. The input image size was adjusted to 1024×1024, and all masks were resized to 256×256. We chose Adam as the optimizer, setting the learning rate to 10−4. The batch size was set to 2, and all models were trained for 30 rounds. On the DEFACTO validation dataset, the edge prediction loss weight in the combined loss β was set to 0.2, and the positive sample loss weight w in the mask prediction loss was set to 5. Additionally, to facilitate larger batch processing, gradient accumulation was set to 8.
3
Comparison with SOTAs
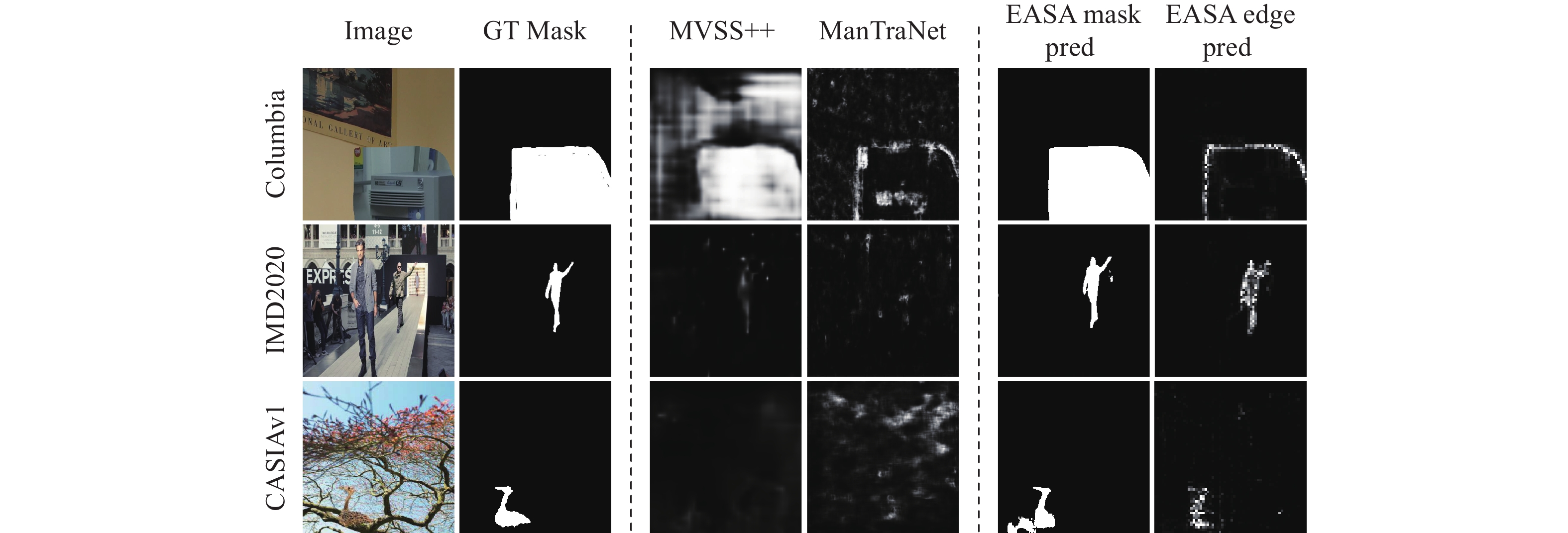
Following the experimental setup of MVSS++, we fixed the F1 threshold at 0.5 to ensure a fair comparison across all models. Table 2 and Figure 6 highlight EASA’s outstanding performance, demonstrating the efficacy of leveraging a foundational model for transfer learning in tasks with limited data. NCL-Net’s success on the NIST16 dataset can be attributed to its training process, which included a portion of NIST data, thereby enhancing its performance. Similarly, MVSS++’s notable success on the COVERAGE dataset is due to its training with both manipulated and real-world data from the CASIAv2 dataset. Since the COVERAGE dataset consists solely of copy-move operations, MVSS++’s extensive training on real-world data has made it particularly adept at detecting copy-move manipulations.
Table
2.
Comparison to State-of-the-Art Methods using the pixel F1 [%] metric.
Figure
6.
Comparison with State-of-the-Art Methods. The SAM model, fine-tuned using our proposed EASA method, demonstrates notably superior performance.
We compared the FLOPs of EASA with MVSS++ and found that our method’s FLOPs are approximately four times that of MVSS++ (0.67T/0.16T≈4.18). Considering the performance improvements we achieved, this difference in FLOPs is acceptable. Overall, EASA significantly outshines other state-of-the-art (SOTA) methods across six public datasets, surpassing MVSS++ by 6.5 points in average pixel-level F1 scores, thereby illustrating SAM’s capability to excel in complex downstream tasks.
4
Ablation Study
Compared to traditional fine-tuning methods, our approach made more specific settings on which parameters to fine-tune. To validate these settings’ rationale, we conducted ablation experiments, as shown in Table 3. Specifically, these ablation settings include:
● Decoder Only: Freezes all parameters except for the Mask Decoder to evaluate if the model’s detection capability primarily stems from the encoder. This setup is crucial for understanding the contribution of the encoder to the model’s overall performance.
● Fully Fine-tune: Acts as the comprehensive baseline, where all necessary parameters are fine-tuned. This is essential for establishing a performance benchmark for comparison with more selective tuning strategies.
● Edge-Attention Only: Adds an Edge-Attention module to the fully fine-tuned model to explore the impact of joint loss supervision. This comparison with the baseline underscores the value of incorporating such supervision in improving performance.
● Adapter Only: Freezes the Image Encoder and fine-tunes an added Adapter module, contrasting with the fully fine-tuned baseline to demonstrate the adapter’s ability to mitigate catastrophic forgetting, thereby showcasing its importance in fine-tuning pre-trained models for new tasks.
Finally, combining the Edge Attention component and the adapter fine-tuning method led to an even higher accuracy improvement. Compared to the baseline, our final version of the EASA method achieved an 8.5-point average F1 accuracy improvement across the six public datasets.
IV.
Conclusion
Our study showcases the application of SAM to IML tasks using our EASA method, achieving top performance across six public datasets. The success hinges on leveraging SAM’s pretraining for minimal data adaptation to IML tasks, emphasizing the foundation model’s representational ability. EASA preserves SAM’s parameters while introducing joint loss supervision and an adapter-based tuning method to prevent catastrophic forgetting. The addition of an edge attention branch enhances edge manipulation detection and clarifies manipulated versus non-manipulated areas. This approach demonstrates the feasibility of adapting foundation models like SAM to complex tasks, proving the value of foundational knowledge and tailored adaptations for specialized task requirements.
Acknowledgements
This work was supported in part by the National Natural Science Foundation of China under Grant No.62271034.
A. Kirillov, E. Mintun, N. Ravi, et al., “Segment anything,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, pp. 3992–4003, 2023.
[2]
F. Ma, X. J. Sun, F. Zhang, et al., “What catch your attention in SAR images: Saliency detection based on soft-superpixel lacunarity cue,” IEEE Transactions on Geoscience and Remote Sensing, vol. 61, article no. 5200817, 2023. DOI: 10.1109/TGRS.2022.3231253
[3]
F. Ma, F. Zhang, D. L. Xiang, et al., “Fast task-specific region merging for SAR image segmentation,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, article no. 5222316, 2022. DOI: 10.1109/TGRS.2022.3141125
[4]
F. Ma, F. Zhang, Q. Yin, et al., “Fast SAR image segmentation with deep task-specific superpixel sampling and soft graph convolution,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, article no. 5214116, 2022. DOI: 10.1109/TGRS.2021.3108585
[5]
M. C. Dai, X. G. Leng, B. L. Xiong, et al., “Sea-land segmentation method for SAR images based on improved BiSeNet,” Journal of Radars, vol. 9, no. 5, pp. 886–897, 2020. DOI: 10.12000/JR20089
[6]
H. X. Zou, M. L. Li, X. Cao, et al., “Superpixel segmentation for PolSAR images based on geodesic distance,” Journal of Radars, vol. 10, no. 1, pp. 20–34, 2021. DOI: 10.12000/JR20121
[7]
F. Zhang, X. J. Sun, F. Ma, et al., “Superpixelwise likelihood ratio test statistic for PolSAR data and its application to built-up area extraction,” ISPRS Journal of Photogrammetry and Remote Sensing, vol. 209, pp. 233–248, 2024. DOI: 10.1016/j.isprsjprs.2024.02.009
[8]
Y. S. Zhou, H. C. Liu, F. Ma, et al., “A sidelobe-aware small ship detection network for synthetic aperture radar imagery,” IEEE Transactions on Geoscience and Remote Sensing, vol. 61, article no. 5205516, 2023. DOI: 10.1109/TGRS.2023.3264231
[9]
F. Gao, L. Z. Kong, R. L. Lang, et al., “SAR target incremental recognition based on features with strong separability,” IEEE Transactions on Geoscience and Remote Sensing, vol. 62, article no. 5202813, 2024. DOI: 10.1109/TGRS.2024.3351636
[10]
Z. Y. Yue, F. Gao, Q. X. Xiong, et al., “A novel semi-supervised convolutional neural network method for synthetic aperture radar image recognition,” Cognitive Computation, vol. 13, no. 4, pp. 795–806, 2021. DOI: 10.1007/s12559-019-09639-x
[11]
H. Q. Huang, F. Gao, J. P. Sun, et al., “Novel category discovery without forgetting for automatic target recognition,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 17, pp. 4408–4420, 2024. DOI: 10.1109/JSTARS.2024.3358449
[12]
Y. H. Huang, X. Yang, L. Liu, et al., “Segment anything model for medical images?,” Medical Image Analysis, vol. 92, article no. 103061, 2024. DOI: 10.1016/j.media.2023.103061
[13]
J. D. Wu, W. Ji, Y. P. Liu, et al., “Medical SAM adapter: Adapting segment anything model for medical image segmentation,” arXiv preprint, arXiv: 2304.12620, 2023.
[14]
J. W. Zhang, K. Ma, S. Kapse, et al., “SAM-path: A segment anything model for semantic segmentation in digital pathology,” in Proceedings of the International Conference on Medical Image Computing and Computer Assisted Intervention, Vancouver, BC, Canada, pp. 161–170, 2023.
[15]
Y. H. Wang, W. G. Zhou, Y. Y. Mao, et al., “Detect any shadow: Segment anything for video shadow detection,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 5, pp. 3782–3794, 2024. DOI: 10.1109/TCSVT.2023.3320688
[16]
H. Dhamo, A. Farshad, I. Laina, et al., “Semantic image manipulation using scene graphs,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, pp. 5212–5221, 2020.
[17]
B. W. Li, X. J. Qi, T. Lukasiewicz, et al., “ManiGAN: Text-guided image manipulation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, pp. 7877–7886, 2020.
[18]
T. Park, J. Y. Zhu, O. Wang, et al., “Swapping autoencoder for deep image manipulation,” Proceedings of the 34th International Conference on Neural Information Processing Systems, vol. Vancouver, article no. BC,Canada,604, 2020.
[19]
Y. Wu, W. AbdAlmageed, and P. Natarajan, “ManTra-Net: Manipulation tracing network for detection and localization of image forgeries with anomalous features,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, pp. 9535–9544, 2019.
[20]
J. H. Bappy, C. Simons, L. Nataraj, et al., “Hybrid LSTM and encoder–decoder architecture for detection of image forgeries,” IEEE Transactions on Image Processing, vol. 28, no. 7, pp. 3286–3300, 2019. DOI: 10.1109/TIP.2019.2895466
[21]
Y. Wu, W. Abd-Almageed, and P. Natarajan, “BusterNet: Detecting copy-move image forgery with source/target localization,” in Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, pp. 170–186, 2018.
[22]
C. B. Dong, X. R. Chen, R. H. Hu, et al., “MVSS-Net: Multi-view multi-scale supervised networks for image manipulation detection,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 3, pp. 3539–3553, 2023. DOI: 10.1109/TPAMI.2022.3180556
[23]
X. Lin, S. Wang, J. H. Deng, et al., “Image manipulation detection by multiple tampering traces and edge artifact enhancement,” Pattern Recognition, vol. 133, article no. 109026, 2023. DOI: 10.1016/j.patcog.2022.109026
[24]
J. Z. Zhou, X. C. Ma, X. Du, et al., “Pre-training-free image manipulation localization through non-mutually exclusive contrastive learning,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, pp. 22289–22299, 2023.
[25]
Y. Y. Zeng, B. W. Zhao, S. Z. Qiu, et al., “Toward effective image manipulation detection with proposal contrastive learning,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 33, no. 9, pp. 4703–4714, 2023. DOI: 10.1109/TCSVT.2023.3247607
[26]
F. F. Niloy, K. K. Bhaumik, and S. S. Woo, “CFL-Net: Image forgery localization using contrastive learning,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, pp. 4631–4640, 2023.
[27]
J. Dong, W. Wang, and T. Tan, “CASIA image tampering detection evaluation database,” 2010, http://forensics.idealtest.org. (查阅网上资料,链接内容与文献不符,请确认) .
[28]
J. Dong, W. Wang, and T. N. Tan, “CASIA image tampering detection evaluation database,” in Proceedings of the IEEE China Summit and International Conference on Signal and Information Processing, Beijing, China, pp. 422–426, 2013.
[29]
T. T. Ng, J. Hsu, and S. F. Chang, “Columbia image splicing detection evaluation dataset,” DVMM Laboratory of Columbia University, CalPhotos Digital Library, 2009. (查阅网上资料, 未能确认文献类型, 请确认文献类型及格式是否正确) .
[30]
B. H. Wen, Y. Zhu, R. Subramanian, et al., “COVERAGE—A novel database for copy-move forgery detection,” in Proceedings of the IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, pp. 161–165, 2016.
[31]
A. Novozámský, B. Mahdian, and S. Saic, “IMD2020: A large-scale annotated dataset tailored for detecting manipulated images,” in Proceedings of the IEEE Winter Conference on Applications of Computer Vision Workshops, Snowmass, CO, USA, pp. 71–80, 2020.
[32]
H. Y. Guan, M. Kozak, E. Robertson, et al., “MFC datasets: Large-scale benchmark datasets for media forensic challenge evaluation,” in Proceedings of the IEEE Winter Applications of Computer Vision Workshops (WACVW), Waikoloa, HI, USA, pp. 63–72, 2019.
[33]
G. Mahfoudi, B. Tajini, F. Retraint, et al., “DEFACTO: Image and face manipulation dataset,” in Proceedings of the 27th European Signal Processing Conference (EUSIPCO), A Coruna, Spain, pp. 1–5, 2019.
[34]
H. D. Li and J. W. Huang, “Localization of deep inpainting using high-pass fully convolutional network,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), pp. 8300–8309, 2019.
[35]
C. Yang, H. Z. Li, F. T. Lin, et al., “Constrained R-CNN: A general image manipulation detection model,” in Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), London, UK, pp. 1–6, 2020.
[36]
P. Zhou, B. C. Chen, X. T. Han, et al., “Generate, segment, and refine: Towards generic manipulation segmentation,” in Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, NY, USA, pp. 13058–13065, 2020.
[37]
X. F. Hu, Z. H. Zhang, Z. Y. Jiang, et al., “SPAN: Spatial pyramid attention network for image manipulation localization,” in Proceedings of the 16th European Conference on Computer Vision, Glasgow, UK, pp. 312–328, 2020.
[38]
M. J. Kwon, I. J. Yu, S. H. Nam, et al., “CAT-Net: Compression artifact tracing network for detection and localization of image splicing,” in Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, pp. 375–384, 2021.



 Zhang Fan: Fan Zhang received the B.E. degree in communication engineering from the Civil Aviation University of China, Tianjin, China, in 2002, the M.S. degree in signal and information processing from Beihang University, Beijing, China, in 2005, and the Ph.D. degree in signal and information processing from Institute of Electronics, Chinese Academy of Sciences, Beijing, China, in 2008. He is currently a Full Professor in Electronic and Information Engineering with the Beijing University of Chemical Technology, Beijing, China. His research interests are remote sensing image processing, high performance computing and artificial intelligence. (Email:
Zhang Fan: Fan Zhang received the B.E. degree in communication engineering from the Civil Aviation University of China, Tianjin, China, in 2002, the M.S. degree in signal and information processing from Beihang University, Beijing, China, in 2005, and the Ph.D. degree in signal and information processing from Institute of Electronics, Chinese Academy of Sciences, Beijing, China, in 2008. He is currently a Full Professor in Electronic and Information Engineering with the Beijing University of Chemical Technology, Beijing, China. His research interests are remote sensing image processing, high performance computing and artificial intelligence. (Email:  Xu Qiming: Qiming Xu is currently pursuing a Master’s degree in Software Engineering at Beijing University of Chemical Technology, Beijing, China. He specializes in Computer Vision (CV). His work centers on the optimization and application of foundational visual models for enhancing image analysis and interpretation capabilities. (Email:
Xu Qiming: Qiming Xu is currently pursuing a Master’s degree in Software Engineering at Beijing University of Chemical Technology, Beijing, China. He specializes in Computer Vision (CV). His work centers on the optimization and application of foundational visual models for enhancing image analysis and interpretation capabilities. (Email:  Hu Wei: Wei Hu received the B.S. and M.S. degrees in computer science from the Dalian University of Science and Technology, Dalian, China, and the Ph.D. degree in computer science from the Tsinghua University, Beijing, China, in 1999, 2002, and 2006, respectively.He is currently an Associate Professor of computer science with the Beijing University of Chemical Technology, Beijing, China. His research interests include computer graphics, computational photography, and scientific visualization. (Email:
Hu Wei: Wei Hu received the B.S. and M.S. degrees in computer science from the Dalian University of Science and Technology, Dalian, China, and the Ph.D. degree in computer science from the Tsinghua University, Beijing, China, in 1999, 2002, and 2006, respectively.He is currently an Associate Professor of computer science with the Beijing University of Chemical Technology, Beijing, China. His research interests include computer graphics, computational photography, and scientific visualization. (Email:  Ma Fei: Fei Ma received the B.S., M.S., and Ph.D. degrees in electronic and information engineering from the Beihang University, Beijing, China, in 2013, 2016, and 2020 respectively. From 2017 to 2018, he was a Research Fellow with Department of Electrical Engineering, McGill University, Montreal, Canada.He is currently a Full Associate Professor at the College of Information Science and Technology, Beijing University of Chemical Technology, Beijing, China. His research interests include synthetic aperture radar (SAR) image processing, machine learning, artificial intelligence, and target detection. (Email:
Ma Fei: Fei Ma received the B.S., M.S., and Ph.D. degrees in electronic and information engineering from the Beihang University, Beijing, China, in 2013, 2016, and 2020 respectively. From 2017 to 2018, he was a Research Fellow with Department of Electrical Engineering, McGill University, Montreal, Canada.He is currently a Full Associate Professor at the College of Information Science and Technology, Beijing University of Chemical Technology, Beijing, China. His research interests include synthetic aperture radar (SAR) image processing, machine learning, artificial intelligence, and target detection. (Email: 
 DownLoad:
DownLoad: