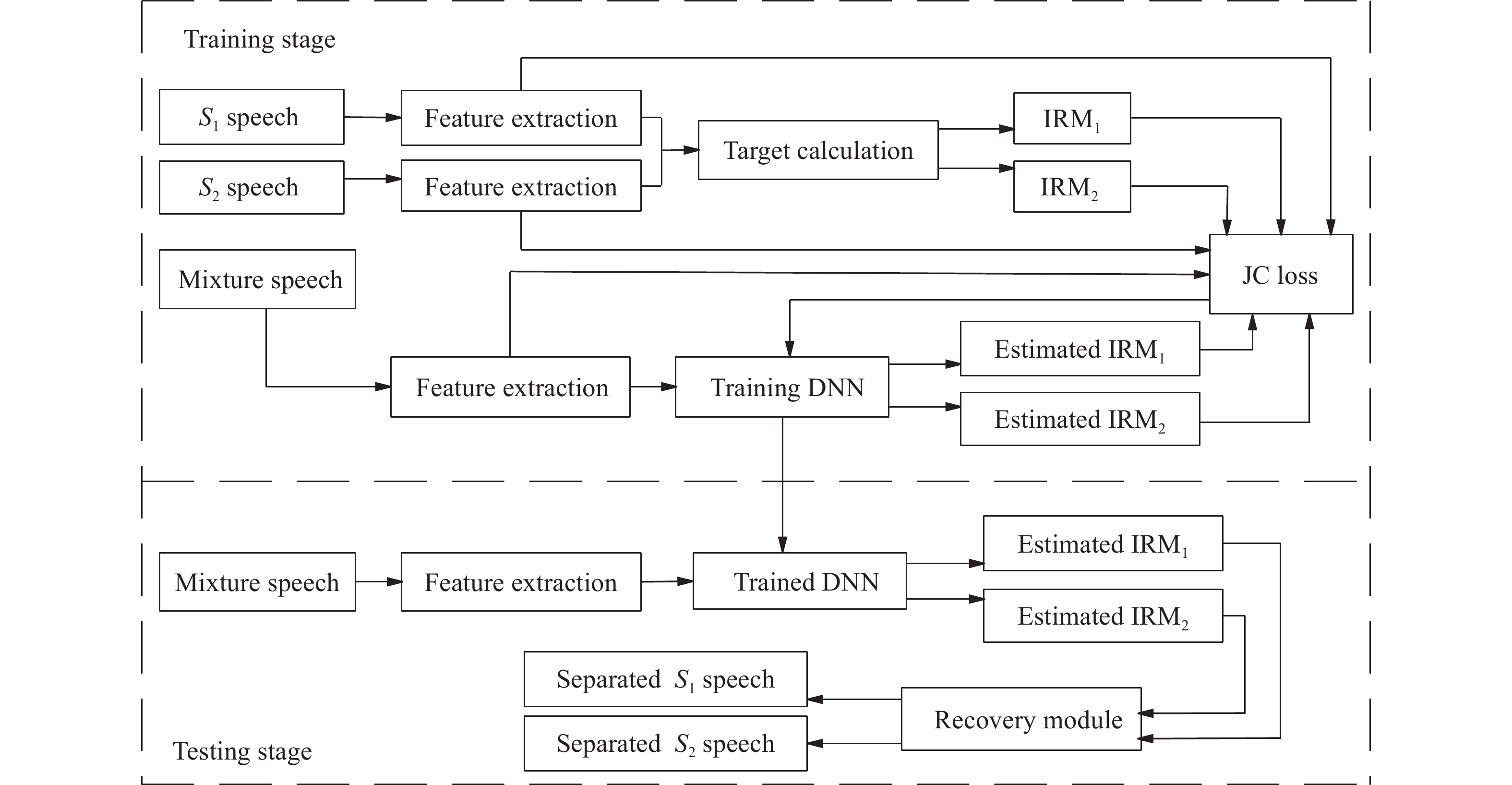
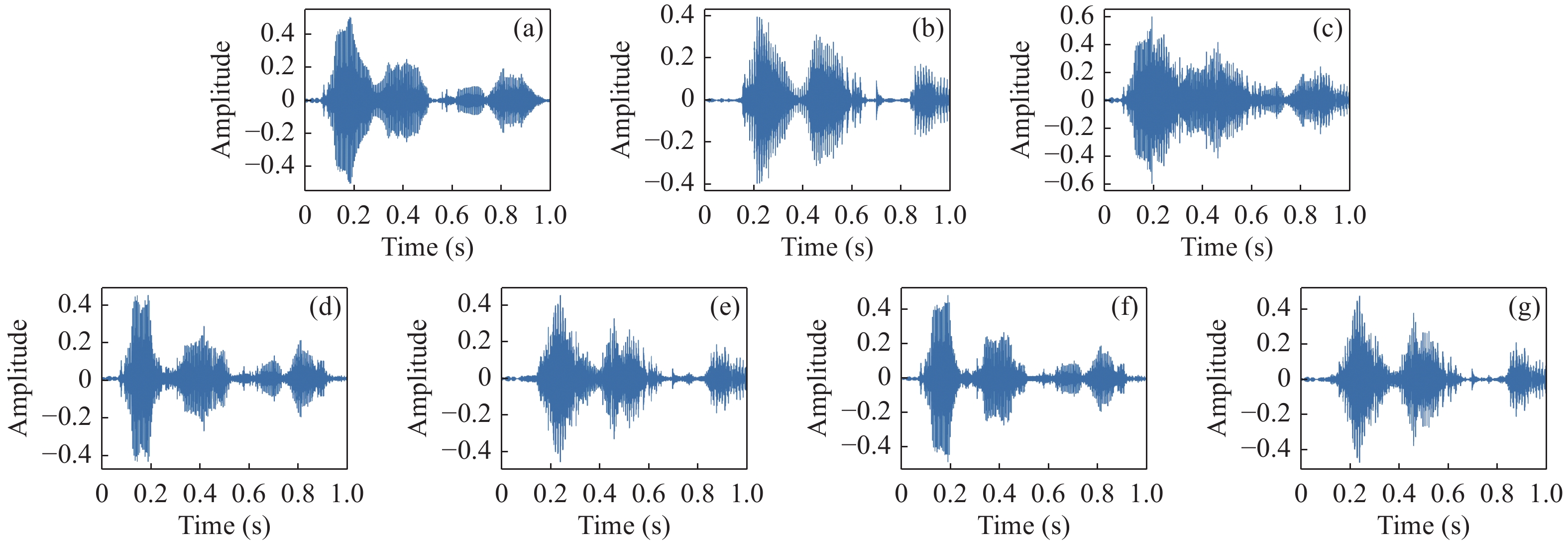
| Citation: | SUN Linhui, LIANG Wenqing, ZHANG Meng, et al., “Monaural Speech Separation Using Dual-Output Deep Neural Network with Multiple Joint Constraint,” Chinese Journal of Electronics, vol. 32, no. 3, pp. 493-506, 2023, doi: 10.23919/cje.2022.00.110

|
| [1] |
J. Du, Y. H. Tu, Y. Xu, et al., “Speech separation of a target speaker based on deep neural networks,” in Proceedings of the 2014 12th International Conference on Signal Processing, Hangzhou, China, pp.473–477, 2014.
|
| [2] |
A. Belouchrani, K. Abed-Meraim, J. F. Cardoso, et al., “A blind source separation technique using second-order statistics,” IEEE Transactions on Signal Processing, vol.45, no.2, pp.434–444, 1997. doi: 10.1109/78.554307
|
| [3] |
M. Yu, A. Rhuma, S. M. Naqvi, et al., “A posture recognition-based fall detection system for monitoring an elderly person in a smart home environment,” IEEE Transactions on Information Technology in Biomedicine, vol.16, no.6, pp.1274–1286, 2012. doi: 10.1109/TITB.2012.2214786
|
| [4] |
J. Du, Y. H. Tu, L. R. Dai, et al., “A regression approach to single-channel speech separation via high-resolution deep neural networks,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol.24, no.8, pp.1424–1437, 2016. doi: 10.1109/TASLP.2016.2558822
|
| [5] |
Y. Sun, W. W. Wang, J. Chambers, et al., “Two-stage monaural source separation in reverberant room environments using deep neural networks,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol.27, no.1, pp.125–139, 2019. doi: 10.1109/TASLP.2018.2874708
|
| [6] |
D. L. Wang, “On ideal binary mask as the computational goal of auditory scene analysis,” in Speech Separation by Humans and Machines, P. Divenyi, Ed., Springer, Boston, MA, USA, pp.181–197, 2005.
|
| [7] |
G. N. Hu and D. L. Wang, “A tandem algorithm for pitch estimation and voiced speech segregation,” IEEE Transactions on Audio, Speech, and Language Processing, vol.18, no.8, pp.2067–2079, 2010. doi: 10.1109/TASL.2010.2041110
|
| [8] |
A. Hyvärinen and E. Oja, “Independent component analysis: Algorithms and applications,” Neural Networks, vol.13, no.4-5, pp.411–430, 2000. doi: 10.1016/S0893-6080(00)00026-5
|
| [9] |
X. L. Zhang and D. L. Wang, “A deep ensemble learning method for monaural speech separation,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol.24, no.5, pp.967–977, 2016. doi: 10.1109/TASLP.2016.2536478
|
| [10] |
Y. X. Wang, A. Narayanan, and D. L. Wang, “On training targets for supervised speech separation,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol.22, no.12, pp.1849–1858, 2014. doi: 10.1109/TASLP.2014.2352935
|
| [11] |
H. Erdogan, J. R. Hershey, S. Watanabe, et al., “Phase-sensitive and recognition-boosted speech separation using deep recurrent neural networks,” in Proceedings of 2015 IEEE International Conference on Acoustics, Speech and Signal Processing, South Brisbane, QLD, Australia, pp.708–712, 2015.
|
| [12] |
D. S. Williamson, Y. X. Wang, and D. L. Wang, “Complex ratio masking for monaural speech separation,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol.24, no.3, pp.483–492, 2016. doi: 10.1109/TASLP.2015.2512042
|
| [13] |
G. Kim, Y. Lu, and P. C. Loizou, “An algorithm that improves speech intelligibility in noise for normal-hearing listeners,” The Journal of the Acoustical Society of America, vol.126, no.3, pp.1486–1494, 2009. doi: 10.1121/1.3184603
|
| [14] |
T. May and T. Dau, “Computational speech segregation based on an auditory-inspired modulation analysis,” The Journal of the Acoustical Society of America, vol.136, no.6, pp.3350–3359, 2014. doi: 10.1121/1.4901711
|
| [15] |
P. S. Huang, M. Kim, M. Hasegawa-Johnson, et al., “Joint optimization of masks and deep recurrent neural networks for monaural source separation,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol.23, no.12, pp.2136–2147, 2015. doi: 10.1109/TASLP.2015.2468583
|
| [16] |
Y. N. Wang, J. Du, L. R. Dai, et al., “A gender mixture detection approach to unsupervised single-channel speech separation based on deep neural networks,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol.25, no.7, pp.1535–1546, 2017. doi: 10.1109/TASLP.2017.2700540
|
| [17] |
M. S. Chauhan, R. Mishra, M. I. Patel, et al., “Speech recognition and separation system using deep learning,” in Proceedings of 2021 International Conference on Innovative Computing, Intelligent Communication and Smart Electrical Systems, Chennai, India, pp.1–5, 2021.
|
| [18] |
S. Wan, “Research on speech separation and recognition algorithm based on deep learning,” in Proceedings of 2021 IEEE International Conference on Power, Intelligent Computing and Systems, Shenyang, China, pp.722–725, 2021.
|
| [19] |
C. H. Fan, J. H. Tao, B. Liu, et al., “End-to-end post-filter for speech separation with deep attention fusion features,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol.28, pp.1303–1314, 2020. doi: 10.1109/TASLP.2020.2982029
|
| [20] |
N. J. Zheng and X. L. Zhang, “Phase-aware speech enhancement based on deep neural networks,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol.27, no.1, pp.63–76, 2019. doi: 10.1109/TASLP.2018.2870742
|
| [21] |
T. G. Kang, J. W. Shin, and N. S. Kim, “DNN-based monaural speech enhancement with temporal and spectral variations equalization,” Digital Signal Processing, vol.74, pp.102–110, 2018. doi: 10.1016/j.dsp.2017.12.002
|
| [22] |
G. Naithani, J. Nikunen, and L. Bramsløw, et al., “Deep neural network based speech separation optimizing an objective estimator of intelligibility for low latency applications,” in Proceedings of the 2018 16th International Workshop on Acoustic Signal Enhancement, Tokyo, Japan, pp.386–390, 2018.
|
| [23] |
L. H. Sun, G. Zhu, and P. A. Li, “Joint constraint algorithm based on deep neural network with dual outputs for single-channel speech separation,” Signal, Image and Video Processing, vol.14, no.7, pp.1387–1395, 2020. doi: 10.1007/s11760-020-01676-6
|
| [24] |
M. Delfarah and D. L. Wang, “Features for masking-based monaural speech separation in reverberant conditions,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol.25, no.5, pp.1085–1094, 2017. doi: 10.1109/TASLP.2017.2687829
|
| [25] |
M. Cooke, J. Barker, S. Cunningham, et al., “An audio-visual corpus for speech perception and automatic speech recognition,” The Journal of the Acoustical Society of America, vol.120, no.5, pp.2421–2424, 2006. doi: 10.1121/1.2229005
|
| [26] |
A. W. Rix, J. G. Beerends, and M. P. Hollier, et al., “Perceptual evaluation of speech quality (PESQ) - A new method for speech quality assessment of telephone networks and codecs,” in Proceedings of 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing, Salt Lake City, UT, USA, pp.749–752, 2001.
|
| [27] |
C. H. Taal, R. C. Hendriks, R. Heusdens, et al., “An algorithm for intelligibility prediction of time-frequency weighted noisy speech,” IEEE Transactions on Audio, Speech, and Language Processing, vol.19, no.7, pp.2125–2136, 2011. doi: 10.1109/TASL.2011.2114881
|
| [28] |
E. Vincent, R. Gribonval, and C. Févotte, “Performance measurement in blind audio source separation,” IEEE Transactions on Audio, Speech, and Language Processing, vol.14, no.4, pp.1462–1469, 2006. doi: 10.1109/TSA.2005.858005
|

Figures(5) / Tables(2)

CJE QR CODE

CIE QR CODE
Copyright © Editorial Office of Chinese Journal of Electronics | 京ICP备12041980号-1 |
Supported by:
Beijing Renhe Information Technology Co. Ltd





 DownLoad:
DownLoad: