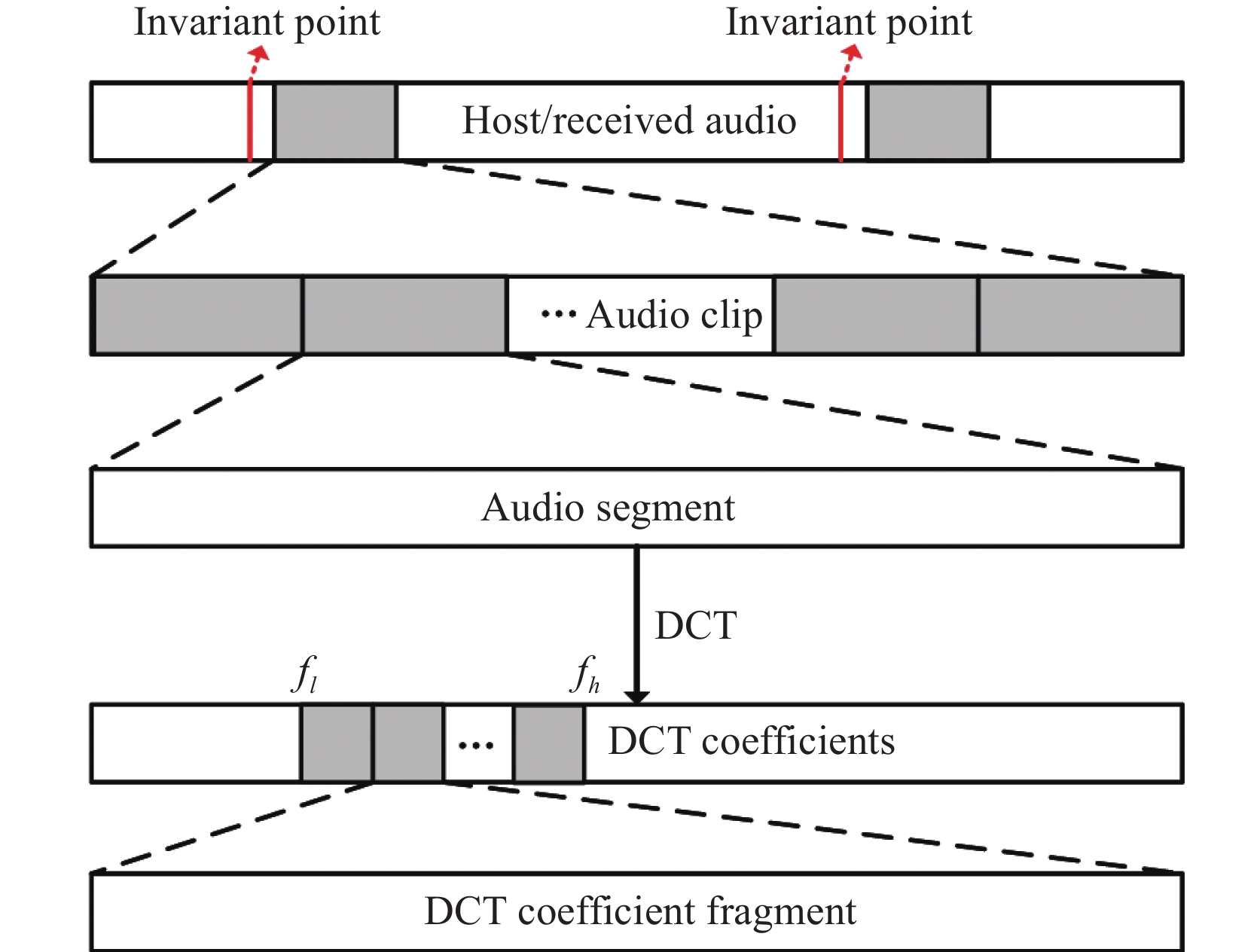
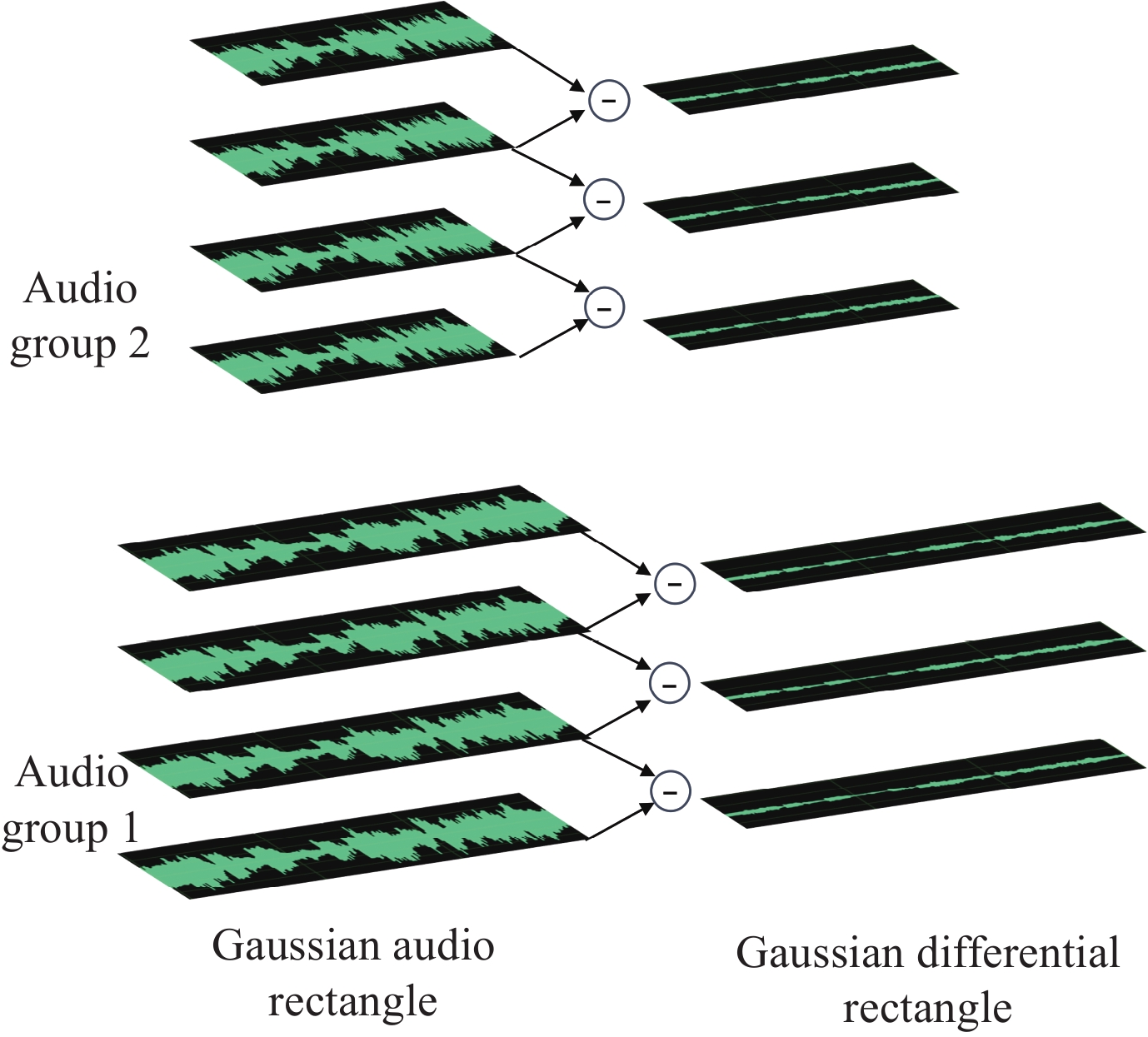
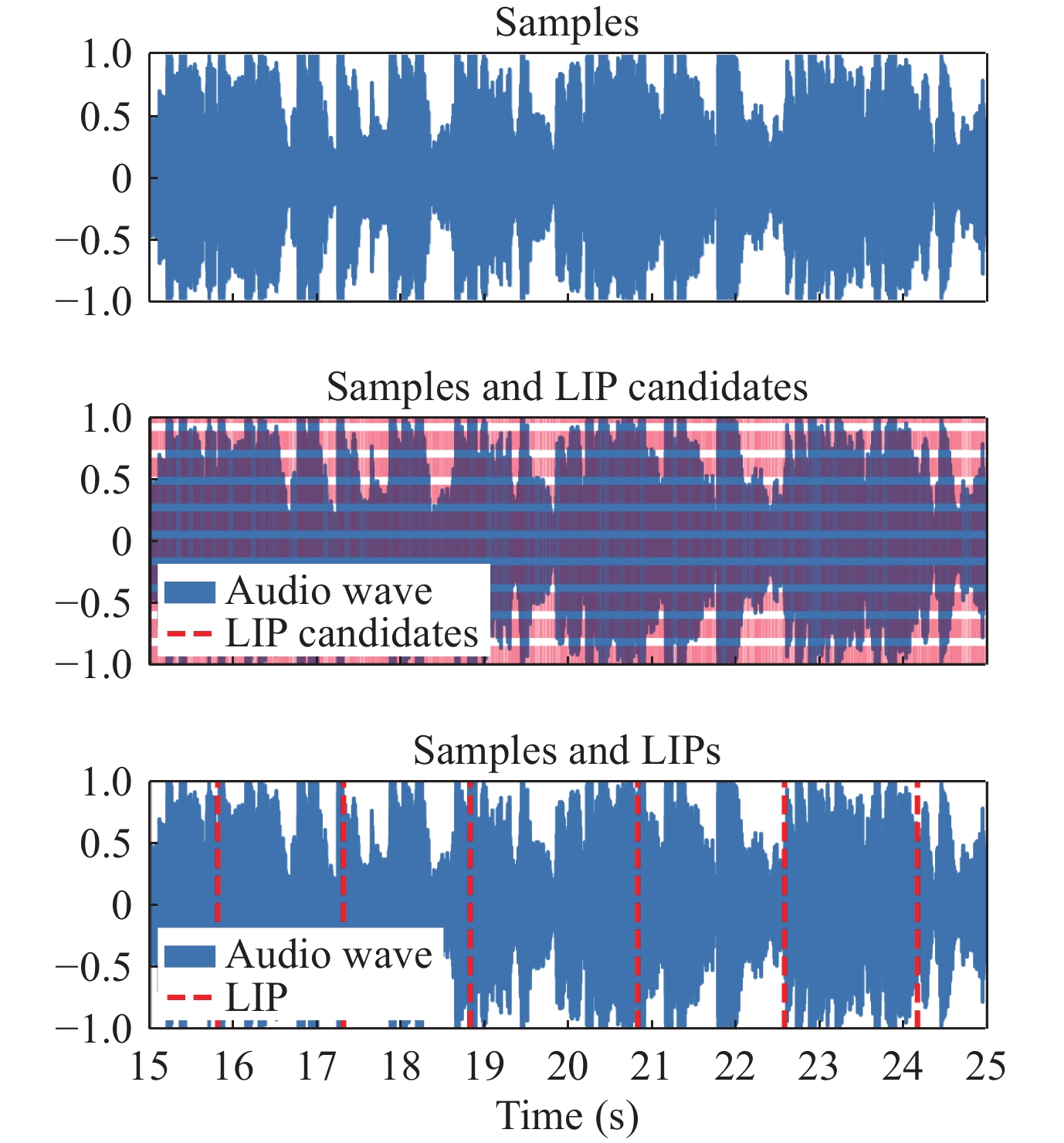
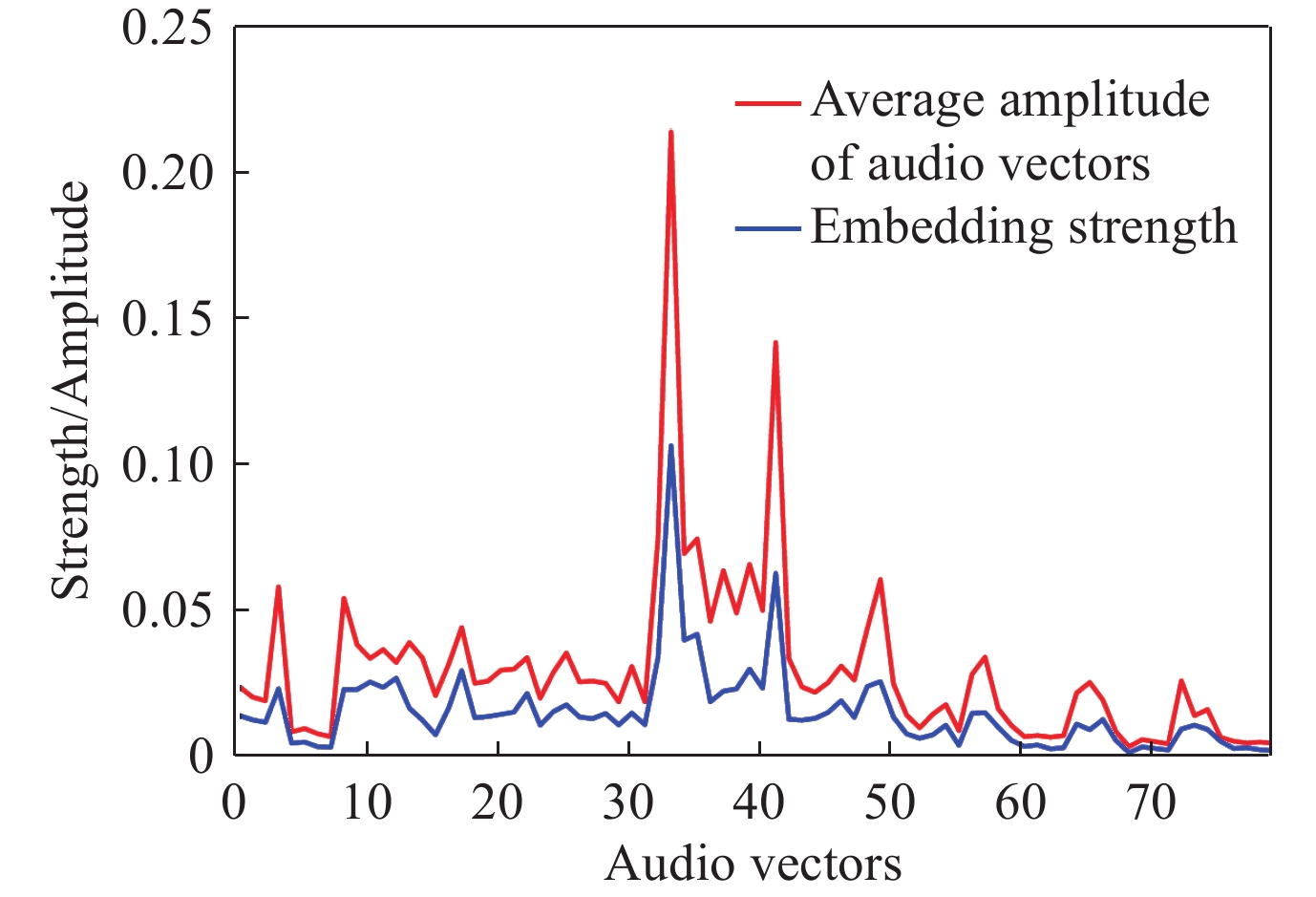
| Citation: | Shiqiang WU, Hu GUAN, Jie LIU, et al., “Imperceptible Audio Watermarking with Local Invariant Points and Adaptive Embedding Strength,” Chinese Journal of Electronics, vol. x, no. x, pp. 1–15, xxxx doi: 10.23919/cje.2023.00.356

|
| [1] |
IFPI, “IFPI releases engaging with music 2022 report,” Report, No. EWM-2022, 2022. (查阅网上资料, 未找到本条文献报告编号信息, 请确认) .
|
| [2] |
G. Hua, J. W. Huang, Y. Q. Shi, et al., “Twenty years of digital audio watermarking—a comprehensive review,” Signal Processing, vol. 128, pp. 222–242, 2016. doi: 10.1016/j.sigpro.2016.04.005
|
| [3] |
K. A. Zhang, A. Cuesta-Infante, L. Xu, et al., “SteganoGAN: High capacity image steganography with GANs,” arXiv preprint, arXiv: 1901.03892, 2019.
|
| [4] |
H. L. Zhang, H. Wang, Y. Z. H. Cao, et al., “Robust data hiding using inverse gradient attention,” arXiv preprint, arXiv: 2011.10850, 2020.
|
| [5] |
GB/T 40985-2021: 2021, Digital Rights Management—Identification and Description of Copyright Resources, Available at: http://www.csres.com/detail/372769.html. (in Chinese).
|
| [6] |
Y. Xiang, I. Natgunanathan, D. Z. Peng, et al., “Spread spectrum audio watermarking using multiple orthogonal PN sequences and variable embedding strengths and polarities,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 26, no. 3, pp. 529–539, 2018. doi: 10.1109/TASLP.2017.2782487
|
| [7] |
S. Q. Wu, Y. Huang, H. Guan, et al., “ECSS: High-embedding-capacity audio watermarking with diversity reception,” Entropy, vol. 24, no. 12, article no. 1843, 2022. doi: 10.3390/e24121843
|
| [8] |
Y. Xiang, I. Natgunanathan, Y. Rong, et al., “Spread spectrum-based high embedding capacity watermarking method for audio signals,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 23, no. 12, pp. 2228–2237, 2015. doi: 10.1109/TASLP.2015.2476755
|
| [9] |
X. R. Zhang, X. Sun, X. M. Sun, et al., “Robust reversible audio watermarking scheme for telemedicine and privacy protection,” Computers, Materials & Continua, vol. 71, no. 2, pp. 3035–3050, 2022. doi: 10.32604/cmc.2022.022304
|
| [10] |
M. Khalil and A. Adib, “Audio watermarking with high embedding capacity based on multiple access techniques,” Digital Signal Processing, vol. 34, pp. 116–125, 2014. doi: 10.1016/j.dsp.2014.07.009
|
| [11] |
W. H. Lu, L. Li, Y. Q. He, et al., “RFPS: A robust feature points detection of audio watermarking for against desynchronization attacks in cyber security,” IEEE Access, vol. 8, pp. 63643–63653, 2020. doi: 10.1109/ACCESS.2020.2984283
|
| [12] |
N. O. Korany, N. M. Elboghdadly, and M. Z. Elabdein, “High capacity, secure audio watermarking technique integrating spread spectrum and linear predictive coding,” Multimedia Tools and Applications, vol. 83, no. 17, pp. 50645–50668, 2024. doi: 10.1007/s11042-023-17630-w
|
| [13] |
S. B. Wang, W. T. Yuan, Z. Zhang, et al., “Synchronous multi-bit audio watermarking based on phase shifting,” in International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, pp. 2700–2704, 2021.
|
| [14] |
A. Phadikar, “Multibit quantization index modulation: A high-rate robust data-hiding method,” Journal of King Saud University-Computer and Information Sciences, vol. 25, no. 2, pp. 163–171, 2013. doi: 10.1016/j.jksuci.2012.11.005
|
| [15] |
I. J. Cox, J. Kilian, F. T. Leighton, et al., “Secure spread spectrum watermarking for multimedia,” IEEE Transactions on Image Processing, vol. 6, no. 12, pp. 1673–1687, 1997. doi: 10.1109/83.650120
|
| [16] |
D. Kirovski and H. S. Malvar, “Spread-spectrum watermarking of audio signals,” IEEE Transactions on Signal Processing, vol. 51, no. 4, pp. 1020–1033, 2003. doi: 10.1109/TSP.2003.809384
|
| [17] |
H. S. Malvar and D. A. F. Florencio, “Improved spread spectrum: A new modulation technique for robust watermarking,” IEEE Transactions on Signal Processing, vol. 51, no. 4, pp. 898–905, 2003. doi: 10.1109/TSP.2003.809385
|
| [18] |
A. Valizadeh and Z. J. Wang, “An improved multiplicative spread spectrum embedding scheme for data hiding,” IEEE Transactions on Information Forensics and Security, vol. 7, no. 4, pp. 1127–1143, 2012. doi: 10.1109/TIFS.2012.2199312
|
| [19] |
N. M. Ngo and M. Unoki, “Watermarking for digital audio based on adaptive phase modulation,” in 13th International Workshop on Digital-Forensics and Watermarking, Taipei, China, pp. 105–119, 2015.
|
| [20] |
N. M. Ngo and M. Unoki, “Method of audio watermarking based on adaptive phase modulation,” IEICE Transactions on Information and Systems, vol. E99.D, no. 1, pp. 92–101, 2016. doi: 10.1587/transinf.2015MUP0019
|
| [21] |
S. Q. Wu, J. W. Huang, D. R. Huang, et al., “Efficiently self-synchronized audio watermarking for assured audio data transmission,” IEEE Transactions on Broadcasting, vol. 51, no. 1, pp. 69–76, 2005. doi: 10.1109/TBC.2004.838265
|
| [22] |
X. Y. Wang, P. P. Niu, and H. Y. Yang, “A robust, digital-audio watermarking method,” IEEE MultiMedia, vol. 16, no. 3, pp. 60–69, 2009. doi: 10.1109/MMUL.2009.44
|
| [23] |
W. Li, X. Y. Xue, and P. Z. Lu, “Localized audio watermarking technique robust against time-scale modification,” IEEE Transactions on Multimedia, vol. 8, no. 1, pp. 60–69, 2006. doi: 10.1109/TMM.2005.861291
|
| [24] |
W. Bender, D. Gruhl, N. Morimoto, et al., “Techniques for data hiding,” IBM Systems Journal, vol. 35, no. 3-4, pp. 313–336, 1996. doi: 10.1147/sj.353.0313
|
| [25] |
M. Arnold, “Audio watermarking: Features, applications and algorithms,” in International Conference on Multimedia and Expo (ICME), New York, NY, USA, pp. 1013–1016, 2000.
|
| [26] |
Y. Xiang, I. Natgunanathan, S. Guo, et al., “Patchwork-based audio watermarking method robust to de-synchronization attacks,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 22, no. 9, pp. 1413–1423, 2014. doi: 10.1109/TASLP.2014.2328175
|
| [27] |
C. Liu, J. Zhang, H. Fang, et al., “DeAR: A deep-learning-based audio re-recording resilient watermarking,” in Proceedings of the 37th AAAI Conference on Artificial Intelligence, Washington, DC, USA, pp. 13201–13209, 2023.
|
| [28] |
A. Nadeau and G. Sharma, “An audio watermark designed for efficient and robust resynchronization after analog playback,” IEEE Transactions on Information Forensics and Security, vol. 12, no. 6, pp. 1393–1405, 2017. doi: 10.1109/TIFS.2017.2661724
|
| [29] |
B. Chen and G. W. Wornell, “Quantization index modulation: A class of provably good methods for digital watermarking and information embedding,” IEEE Transactions on Information Theory, vol. 47, no. 4, pp. 1423–1443, 2001. doi: 10.1109/18.923725
|
| [30] |
D. Gruhl, A. Lu, and W. Bender, “Echo hiding,” in Proceedings of the First International Workshop on Information Hiding, Cambridge, UK, pp. 295–315, 1996.
|
| [31] |
K. Imabeppu, D. Hamada, and M. Unoki, “Embedding limitations with audio-watermarking method based on cochlear-delay characteristics,” in Fifth International Conference on Intelligent Information Hiding and Multimedia Signal Processing, Kyoto, Japan, pp. 82–85, 2009.
|
| [32] |
M. Unoki and R. Miyauchi, “Robust, blindly-detectable, and semi-reversible technique of audio watermarking based on cochlear delay characteristics,” IEICE Transactions on Information and Systems, vol. E98.D, no. 1, pp. 38–48, 2015. doi: 10.1587/transinf.2014MUP0017
|
| [33] |
G. Hua, J. Goh, and V. L. L. Thing, “Time-spread echo-based audio watermarking with optimized imperceptibility and robustness,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 23, no. 2, pp. 227–239, 2015. doi: 10.1109/TASLP.2014.2387385
|
| [34] |
M. J. Hwang, J. Lee, M. Lee, et al., “SVD-based adaptive QIM watermarking on stereo audio signals,” IEEE Transactions on Multimedia, vol. 20, no. 1, pp. 45–54, 2018. doi: 10.1109/TMM.2017.2721642
|
| [35] |
G. F. Zhang, L. L. Zheng, Z. P. Su, et al., “M-sequences and sliding window based audio watermarking robust against large-scale cropping attacks,” IEEE Transactions on Information Forensics and Security, vol. 18, pp. 1182–1195, 2023. doi: 10.1109/TIFS.2023.3236456
|
| [36] |
Z. Liu and A. Inoue, “Audio watermarking techniques using sinusoidal patterns based on pseudorandom sequences,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 13, no. 8, pp. 801–812, 2003. doi: 10.1109/TCSVT.2003.815960
|
| [37] |
C. Baras, N. Moreau, and P. Dymarski, “Controlling the inaudibility and maximizing the robustness in an audio annotation watermarking system,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 14, no. 5, pp. 1772–1782, 2006. doi: 10.1109/TASL.2006.879808
|
| [38] |
Z. P. Su, G. F. Zhang, F. Yue, et al., “SNR-constrained heuristics for optimizing the scaling parameter of robust audio watermarking,” IEEE Transactions on Multimedia, vol. 20, no. 10, pp. 2631–2644, 2018. doi: 10.1109/TMM.2018.2812599
|
| [39] |
Z. H. Liu, Y. K. Huang, and J. W. Huang, “Patchwork-based audio watermarking robust against de-synchronization and recapturing attacks,” IEEE Transactions on Information Forensics and Security, vol. 14, no. 5, pp. 1171–1180, 2019. doi: 10.1109/TIFS.2018.2871748
|
| [40] |
C. M. Pun and X. C. Yuan, “Robust segments detector for de-synchronization resilient audio watermarking,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 21, no. 11, pp. 2412–2424, 2013. doi: 10.1109/TASL.2013.2279312
|
| [41] |
A. N. Lemma, J. Aprea, W. Oomen, et al., “A temporal domain audio watermarking technique,” IEEE Transactions on Signal Processing, vol. 51, no. 4, pp. 1088–1097, 2003. doi: 10.1109/TSP.2003.809372
|
| [42] |
O. T. C. Chen and W. C. Wu, “Highly robust, secure, and perceptual-quality echo hiding scheme,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 16, no. 3, pp. 629–638, 2008. doi: 10.1109/TASL.2007.913022
|
| [43] |
W. N. Lie and L. C. Chang, “Robust and high-quality time-domain audio watermarking based on low-frequency amplitude modification,” IEEE Transactions on Multimedia, vol. 8, no. 1, pp. 46–59, 2006. doi: 10.1109/TMM.2005.861292
|
| [44] |
S. J. Xiang and J. W. Huang, “Histogram-based audio watermarking against time-scale modification and cropping attacks,” IEEE Transactions on Multimedia, vol. 9, no. 7, pp. p.1357–1372, 2007. doi: 10.1109/TMM.2007.906580
|
| [45] |
Y. Xiang, D. Z. Peng, I. Natgunanathan, et al., “Effective pseudonoise sequence and decoding function for imperceptibility and robustness enhancement in time-spread echo-based audio watermarking,” IEEE Transactions on Multimedia, vol. 13, no. 1, pp. 2–13, 2011. doi: 10.1109/TMM.2010.2080668
|
| [46] |
A. Spanias, T. Painter, and V. Atti, Audio Signal Processing and Coding. John Wiley & Sons, Hoboken, NJ, USA, 2007, doi: 10.1002/0470041978.
|
| [47] |
M. Defferrard, K. Benzi, P. Vandergheynst, et al., “FMA: A dataset for music analysis,” in Proceedings of the 18th International Society for Music Information Retrieval Conference, Suzhou, China, pp. 316–323, 2017.
|
| [48] |
GY/T 349-2021: 2021, Method for Objective Measurements of Perceived Audio Quality, Available at: https://www.abp2003.cn/attach/0/0434adb8011e46878cd87c4258f67949.pdf. (in Chinese).
|
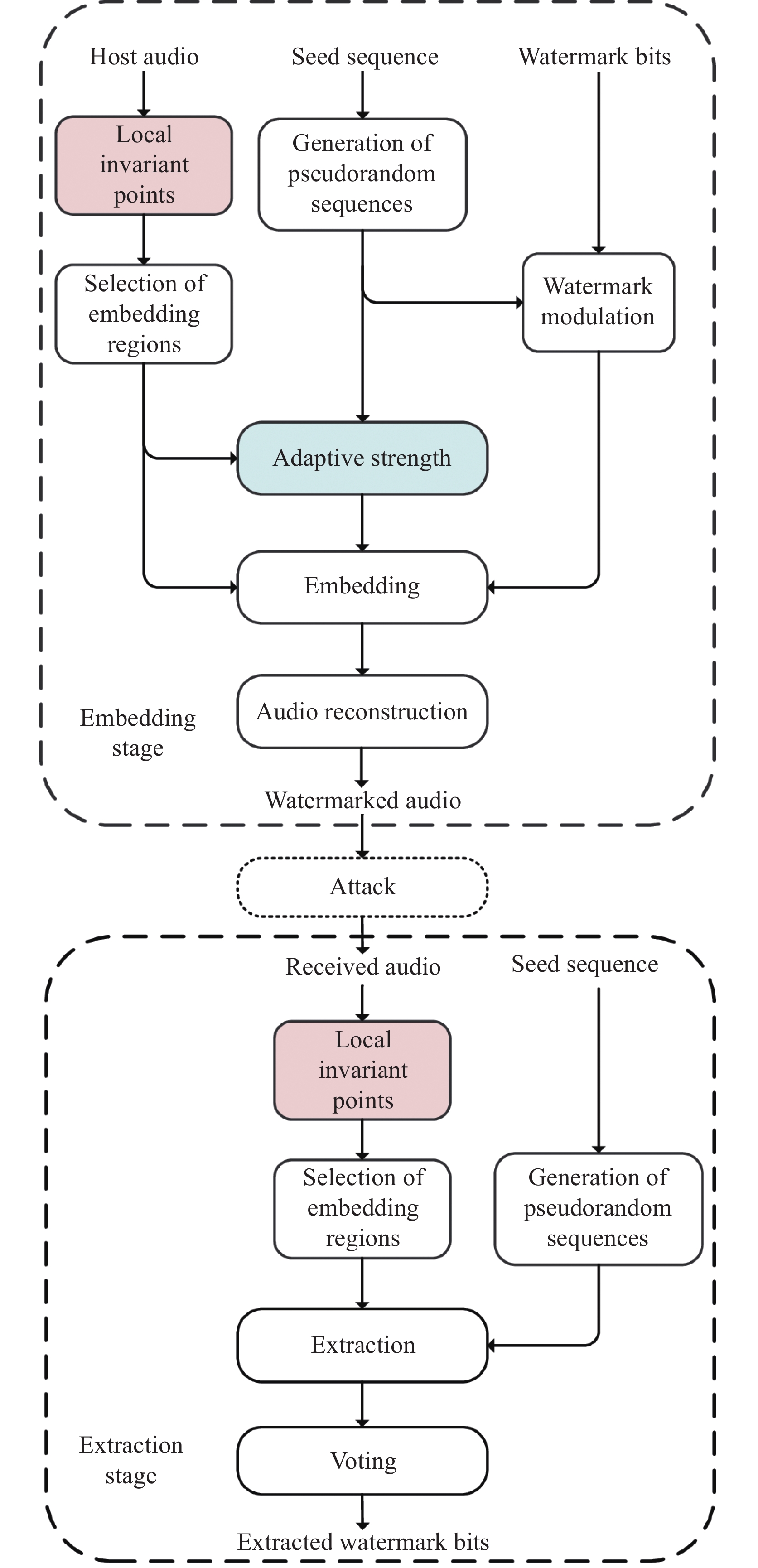
Figures(9) / Tables(9)

CJE QR CODE

CIE QR CODE
Copyright © Editorial Office of Chinese Journal of Electronics | 京ICP备12041980号-1 |
Supported by:
Beijing Renhe Information Technology Co. Ltd




 DownLoad:
DownLoad: